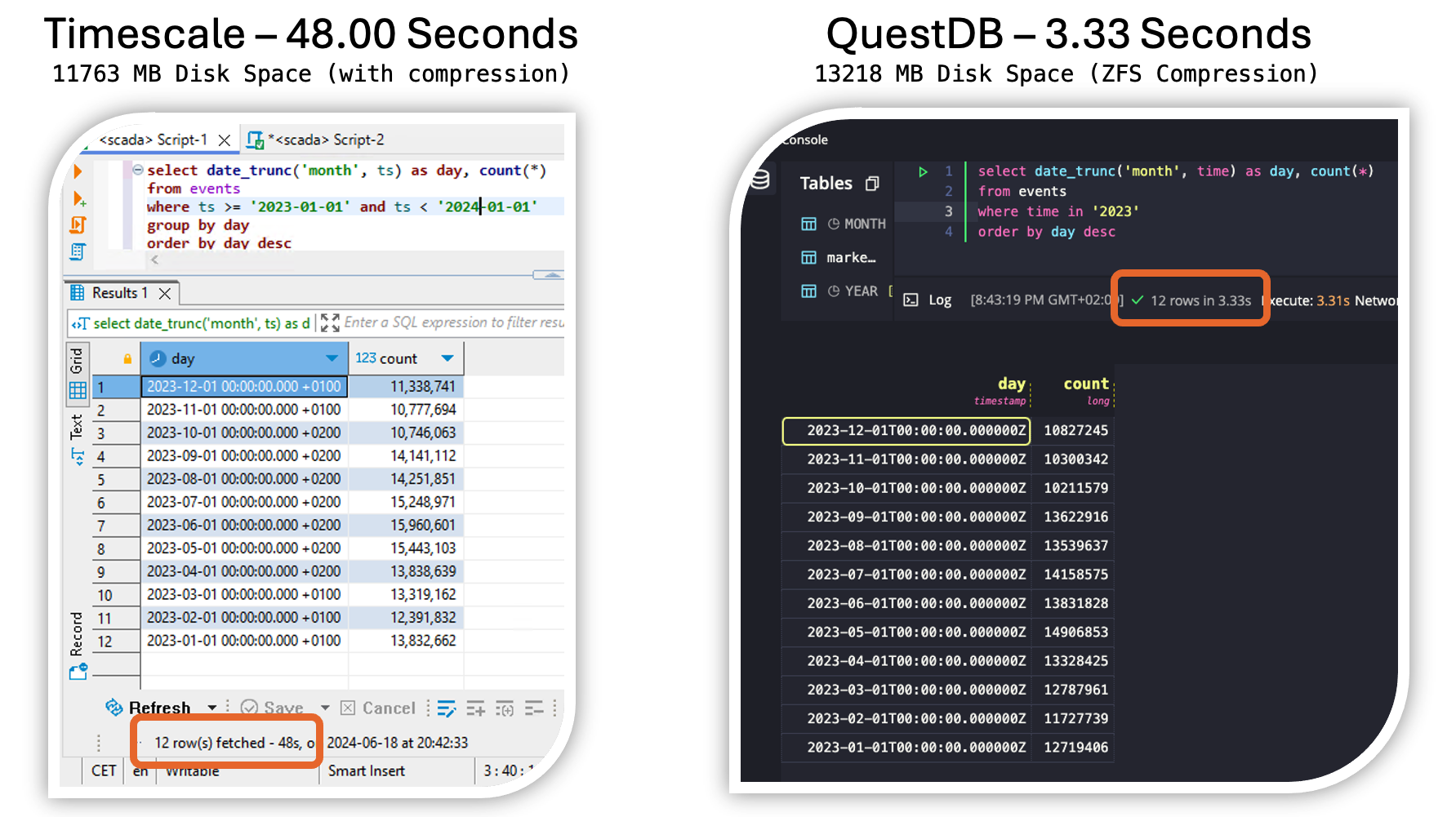
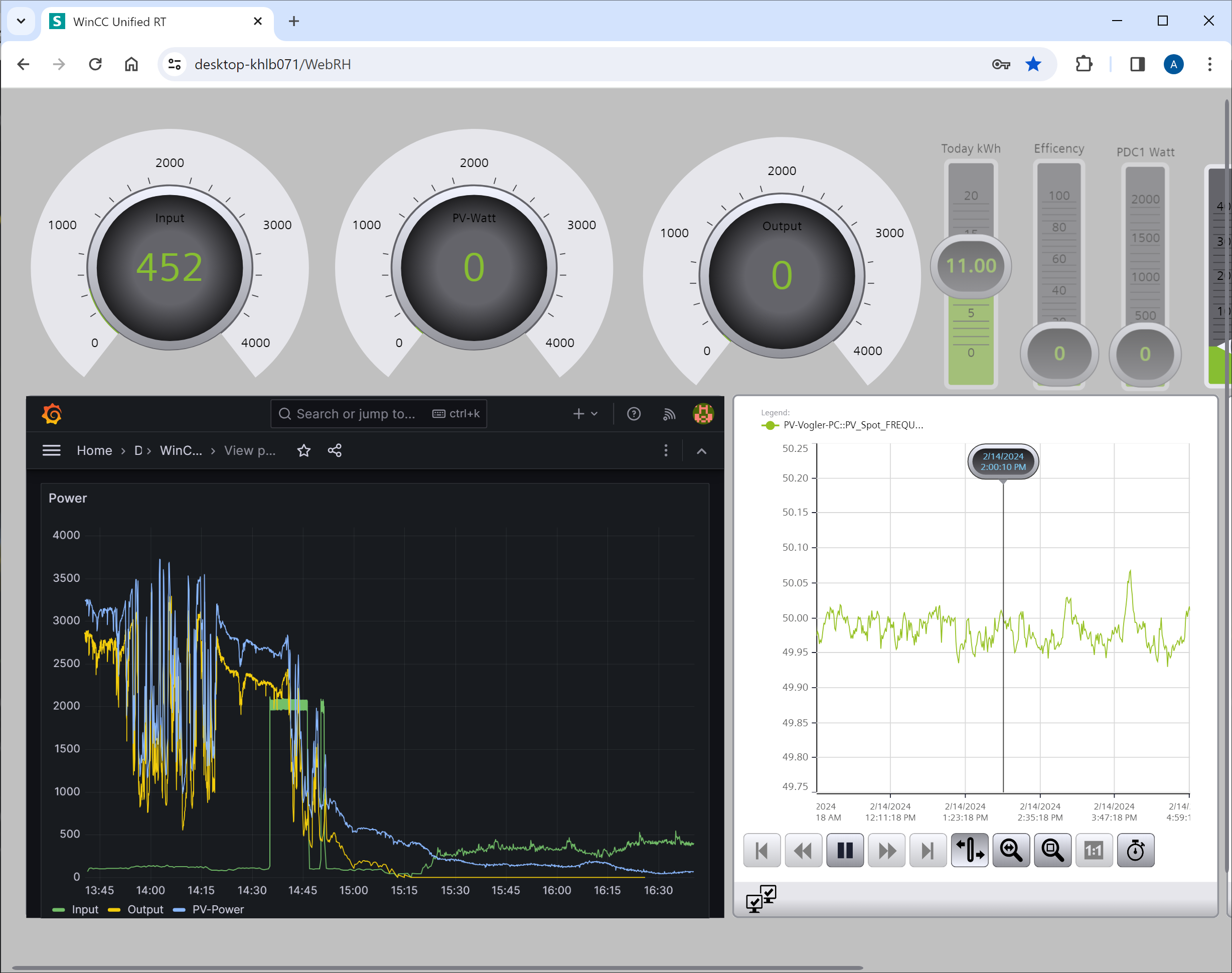
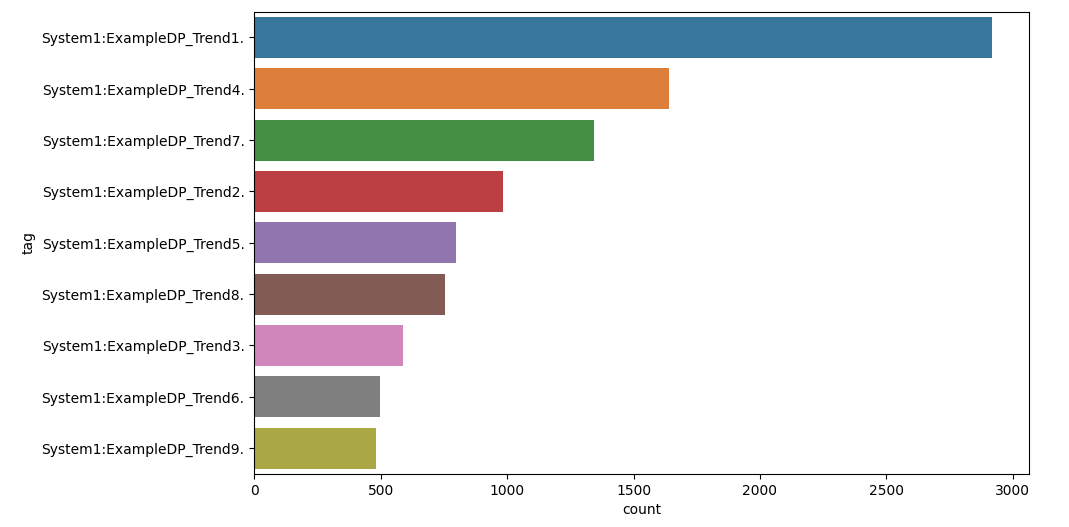
Because MonsterMQ can store topic values directly in PostgreSQL/Timescale, you can instantly create dashboards with Grafana! 📊
Here’s a simple example:
👉 Check out the live dashboard
It’s super easy to get started. Use the public available MonsterMQ at test.monstermq.com at port 1883. Just publish a JSON string to any topic under “Test”, like “Test/Sensor1” with a payload like this: {“value”: 1}, and you’ll see the value reflected in the Grafana dashboard in real time.
I’m currently publishing temperature sensor values to the public broker from my home automation using automation-gateway.com. Just that you see some values in the dashboard.
So, if you need a broker to store your IoT data directly into TimescaleDB without the need for any additional components, consider using MonsterMQ. It’s free and available at MonsterMQ.com.
Here is the exmaple docker-compose.yml file of the public availble test.monstermq.com broker:
services:
timescale:
image: timescale/timescaledb:latest-pg16
restart: unless-stopped
ports:
- "5432:5432"
volumes:
- /data/timescale:/var/lib/postgresql/data
environment:
POSTGRES_USER: system
POSTGRES_PASSWORD: xxx
monstermq:
image: rocworks/monstermq:latest
restart: unless-stopped
ports:
- 1883:1883
volumes:
- ./config.yaml:/app/config.yaml
command: ["+cluster", "-log INFO"]
pgadmin:
image: dpage/pgadmin4
restart: unless-stopped
environment:
PGADMIN_DEFAULT_EMAIL: andreas.vogler@rocworks.at
PGADMIN_DEFAULT_PASSWORD: xxx
volumes:
- /data/pgadmin:/var/lib/pgadmin/storage
ports:
- "8080:80"
grafana:
image: grafana/grafana
restart: unless-stopped
ports:
- 80:3000Here is the MonsterMQ config.yml file:
Port: 1883
SSL: false
WS: true
TCP: true
SessionStoreType: POSTGRES
RetainedStoreType: POSTGRES
SparkplugMetricExpansion:
Enabled: true
ArchiveGroups:
- Name: "All"
Enabled: true
TopicFilter: [ "#" ]
RetainedOnly: false
LastValType: POSTGRES
ArchiveType: NONE
- Name: "Test"
Enabled: true
TopicFilter: [ "Test/#" ]
RetainedOnly: false
LastValType: NONE
ArchiveType: POSTGRES
Postgres:
Url: jdbc:postgresql://timescale:5432/monster
User: system
Pass: xxxGive it a try and let me know what you think!
#iot #mqtt #monstermq #timescale #postgresql #grafana