The integration of SCADA with Spark and WinCC Open Architecture offers a powerful and versatile solution that combines real-time data processing, advanced analytics, scalability, and flexibility. This combination empowers you to optimize industrial processes, make data-driven decisions, and stay ahead in a rapidly evolving technological landscape.
By utilizing my 5-year-old project that implemented a native Java manager for WinCC Open Architecture, I have enabled the integration of SCADA with Spark for the current WinCC OA Version 3.19.
Very simple example is to analyze tags and the corresponding amount of values in your SCADA system can provide valuable insights into the distribution and characteristics of the data.
res = spark.sql('SELECT tag, count(*) count FROM events GROUP BY tag ORDER by count(*) DESC')
data = res.toPandas()
plt.figure( figsize = ( 10, 6 ) )
sns.barplot( x="count", y="tag", data=data)
plt.show()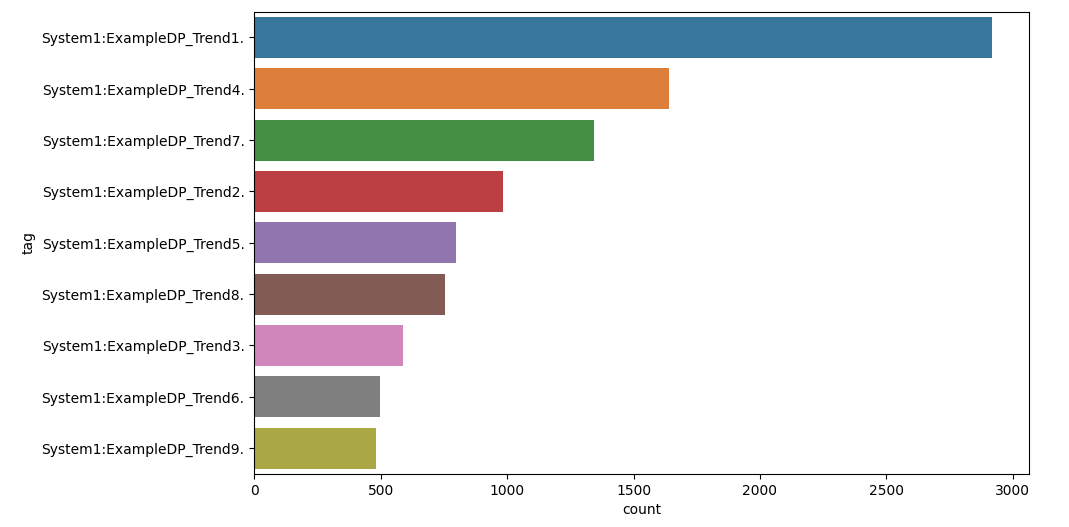
Another simple example is to calculate the moving average of 10 preceding and following values for a given data point in a time series, you can use a sliding window approach:
data = spark.sql("""
SELECT ROUND(value,2) as value,
AVG(value) OVER (PARTITION BY tag ORDER BY ts
ROWS BETWEEN 10 PRECEDING AND 10 FOLLOWING) avg
FROM events
WHERE tag = 'System1:ExampleDP_Trend2.'
ORDER BY ts DESC
LIMIT 100
""").toPandas()
data = data.reset_index().rename(columns={"index": "nr"})
sns.lineplot(data=data, x='nr', y='value', label='Value')
sns.lineplot(data=data, x='nr', y='avg', label='Average')
plt.show()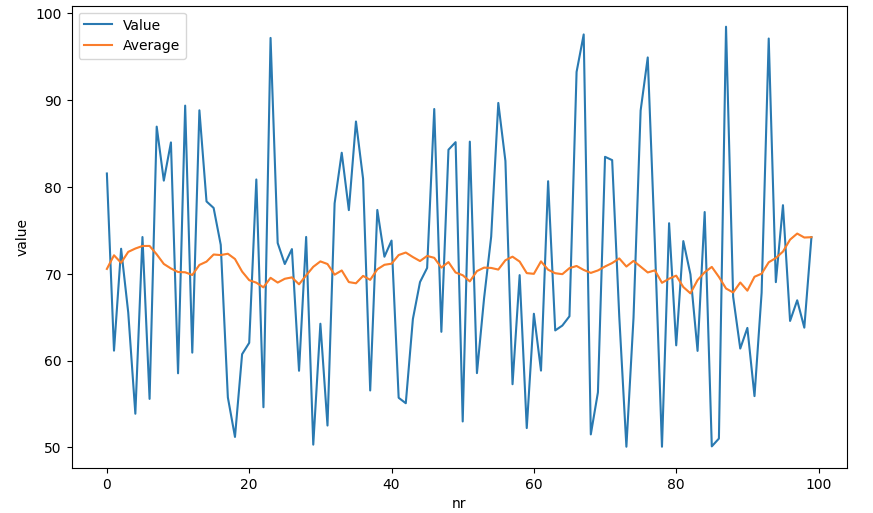
By leveraging the distributed file system, you can take advantage of Spark’s parallel processing capabilities. The distributed file system ensures that the data frame is partitioned and distributed across the nodes of the Spark cluster, enabling simultaneous processing of data in parallel. This distributed approach enhances performance and scalability, allowing for efficient handling of large volumes of real-time SCADA data.
I have achieved real-time data streaming from WinCC OA to a Spark cluster with a Websocket-Server based on the Java manager. This streaming process involves continuously transferring SCADA real-time data from the WinCC OA system to the Spark cluster for further processing and analysis.
url='wss://192.168.1.190:8443/winccoa?username=root&password='
ws = create_connection(url, sslopt={"cert_reqs": ssl.CERT_NONE})
def read():
while True:
on_message(ws.recv())
Thread(target=read).start()
cmd={'DpQueryConnect': {'Id': 1, 'Query':"SELECT '_online.._value' FROM 'ExampleDP_*.'", 'Answer': False}}
ws.send(json.dumps(cmd))Once the data is received by the Spark cluster, I store it as a data frame on the distributed file system (DFS). A data frame is a distributed collection of data organized into named columns, similar to a table in a relational database. Storing the data frame on the distributed file system ensures data persistence and allows for efficient processing and retrieval.
schema = StructType([
StructField("ts", TimestampType(), nullable=False),
StructField("tag", StringType(), nullable=False),
StructField("value", FloatType(), nullable=False)
])
df = spark.createDataFrame(spark.sparkContext.emptyRDD(), schema)bulk = []
last = datetime.datetime.now()
def on_message(message):
global bulk, last, start
data = json.loads(message)
if "DpQueryConnectResult" in data:
values = data["DpQueryConnectResult"]["Values"]
for tag, value in values:
#print(tag, value)
data = {"ts": datetime.datetime.now(), "tag": tag, "value": value}
bulk.append(data)
now =datetime.datetime.now()
time = datetime.datetime.now() - last
if time.total_seconds() > 10 or len(bulk) >= 1000:
last = now
# Create a new DataFrame with the received data
new_df = spark.createDataFrame(bulk, schema)
new_df.write \
.format("csv") \
.option("header", "true") \
.mode("append") \
.save("events.csv")
bulk = []Once the SCADA data is stored as a distributed data frame on the Spark cluster’s distributed file system, you can leverage Spark’s parallel processing capabilities to efficiently process the data in parallel.
df = spark.read \
.format("csv") \
.option("header", "true") \
.option("timezone", "UTC") \
.schema(schema) \
.load("events.csv")
df.createOrReplaceTempView("events")By combining SCADA (Supervisory Control and Data Acquisition) with Spark’s powerful data processing capabilities, I have created a solution that can handle large volumes of real-time data efficiently. This enables faster and more accurate decision-making based on the insights derived from the processed data.