The broker now has a NATS bridge integrated – you can receive messages from NATS and also publish to NATS.
For example, with simple wildcard subscriptions you can bring your topics straight into NATS – no extra glue code needed!
A big thanks to Kevin Joosten for this contribution!
‼️ And I added that MMQ can act as a NATS Server (NATS core 1.0). So, now NATS clients can connect to MonsterMQ and pub/sub to topics. NATS protocol is super simple.
This opens up some new integration scenarios where MQTT and NATS need to coexist in the same architecture.
Star it if you like it – and drop me a message if you’re using MonsterMQ in your setup!
Category Archives: MonsterMQ
MQTT Broker with i3x? – MonsterMQ got it!
A i3x server integrated directly into MonsterMQ!
What’s happening under the hood:
👉 MQTT topics are stored in memory
👉 Historical values are persisted in MongoDB
Those features have been available in MonsterMQ for a long time…
The i3x interface just exposes all of that data via the i3x protocol!
💡 This means you get a full MQTT broker with structured, queryable data access via i3x – all in one place.
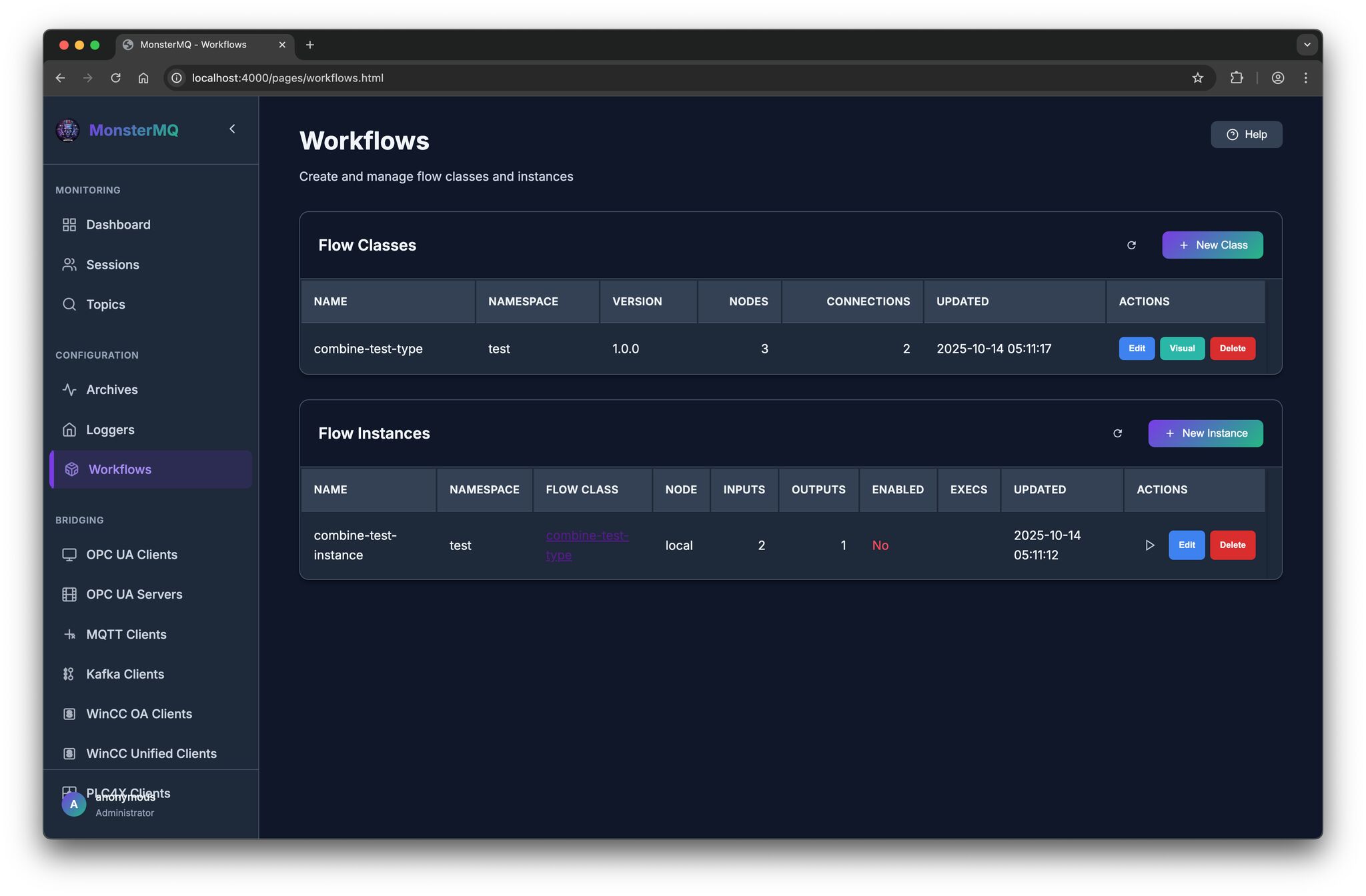
🧌 New Features in MonsterMQ – Flow Engine & Data Logging!
I’ve added a first version a workflow engine that lets you define custom business logic directly inside the broker:
🔹 React on multiple input topics
🔹 Write your logic in JavaScript, more functions
🔹 Publish results to output topics
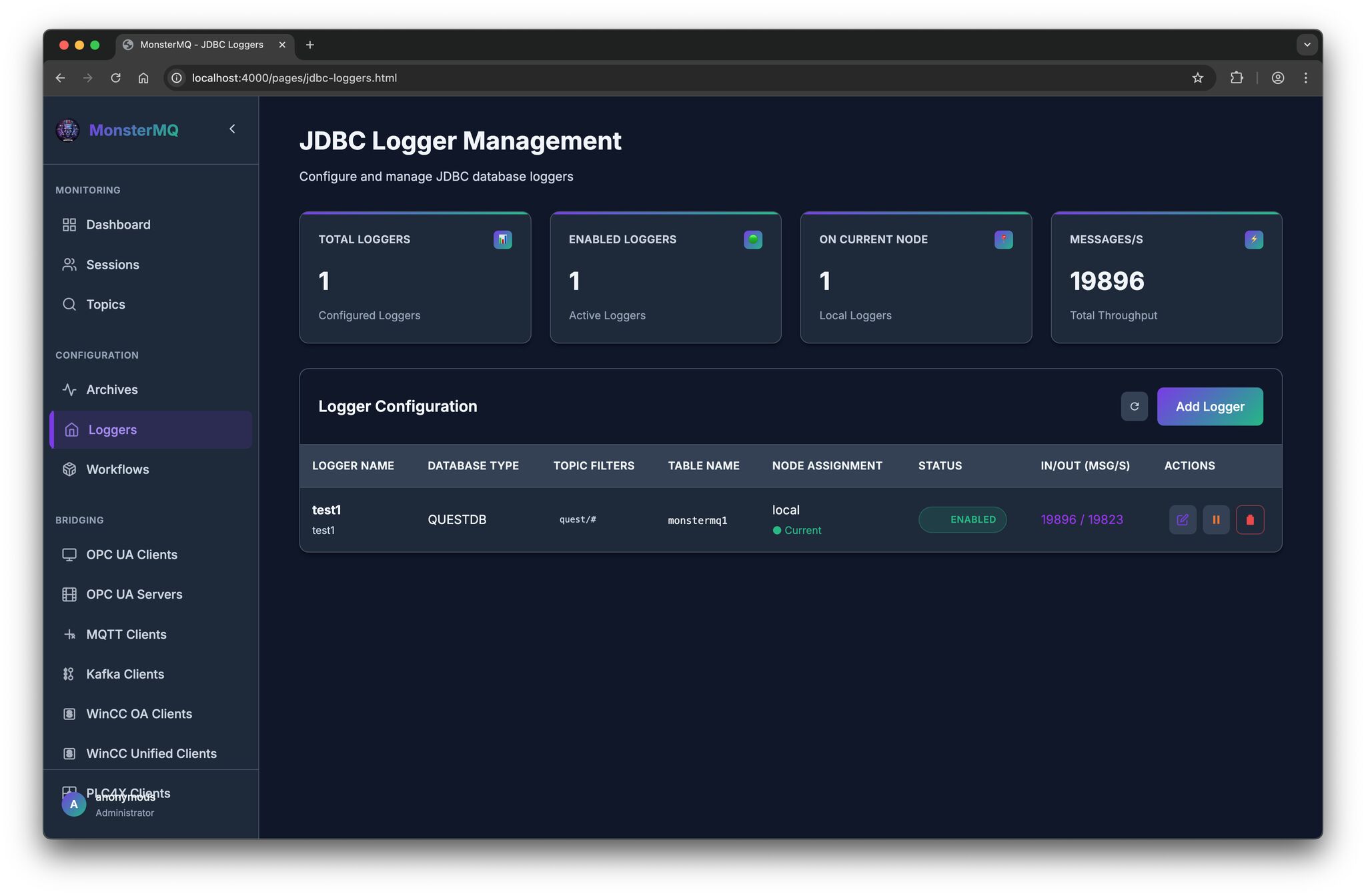
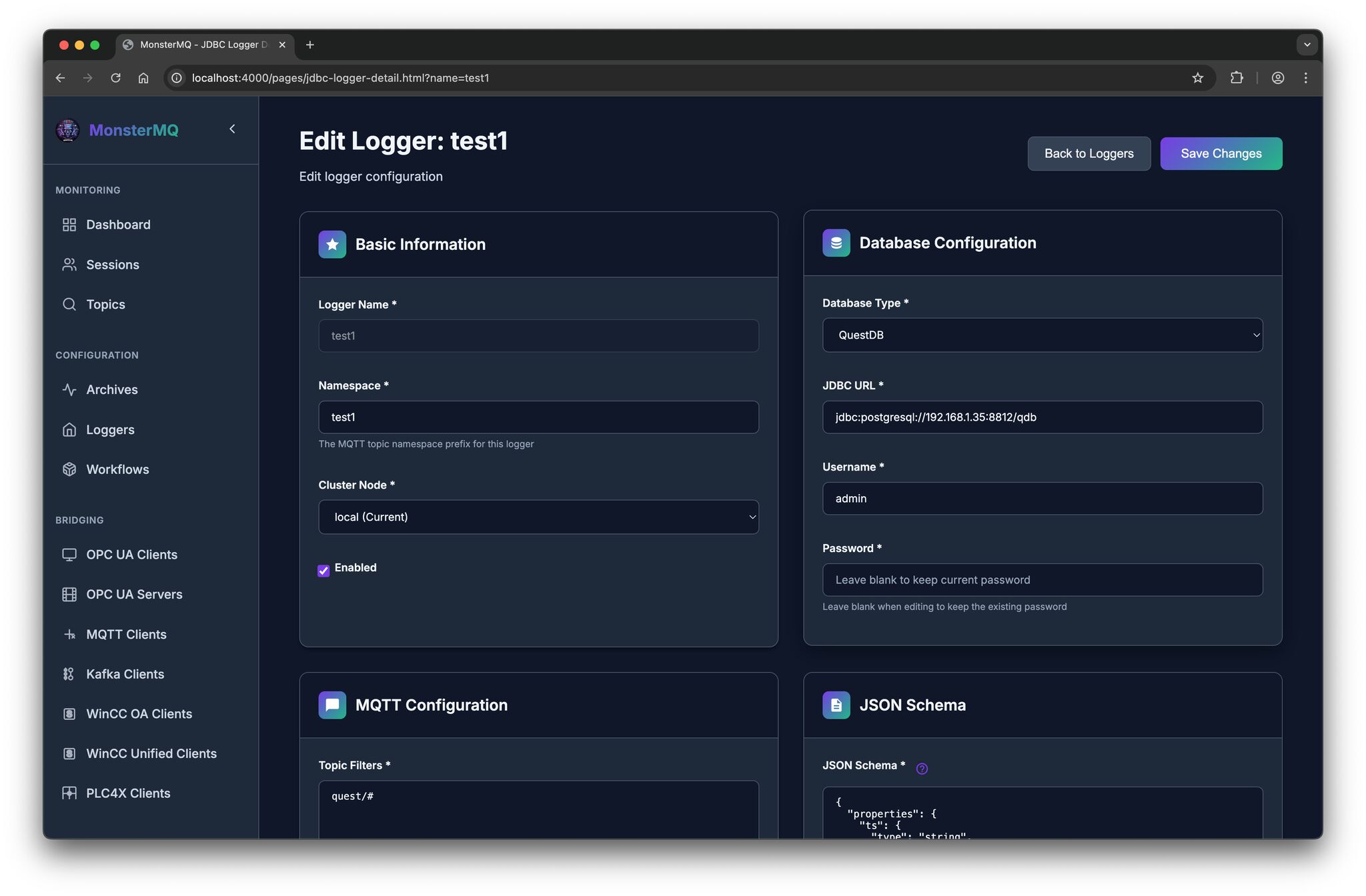
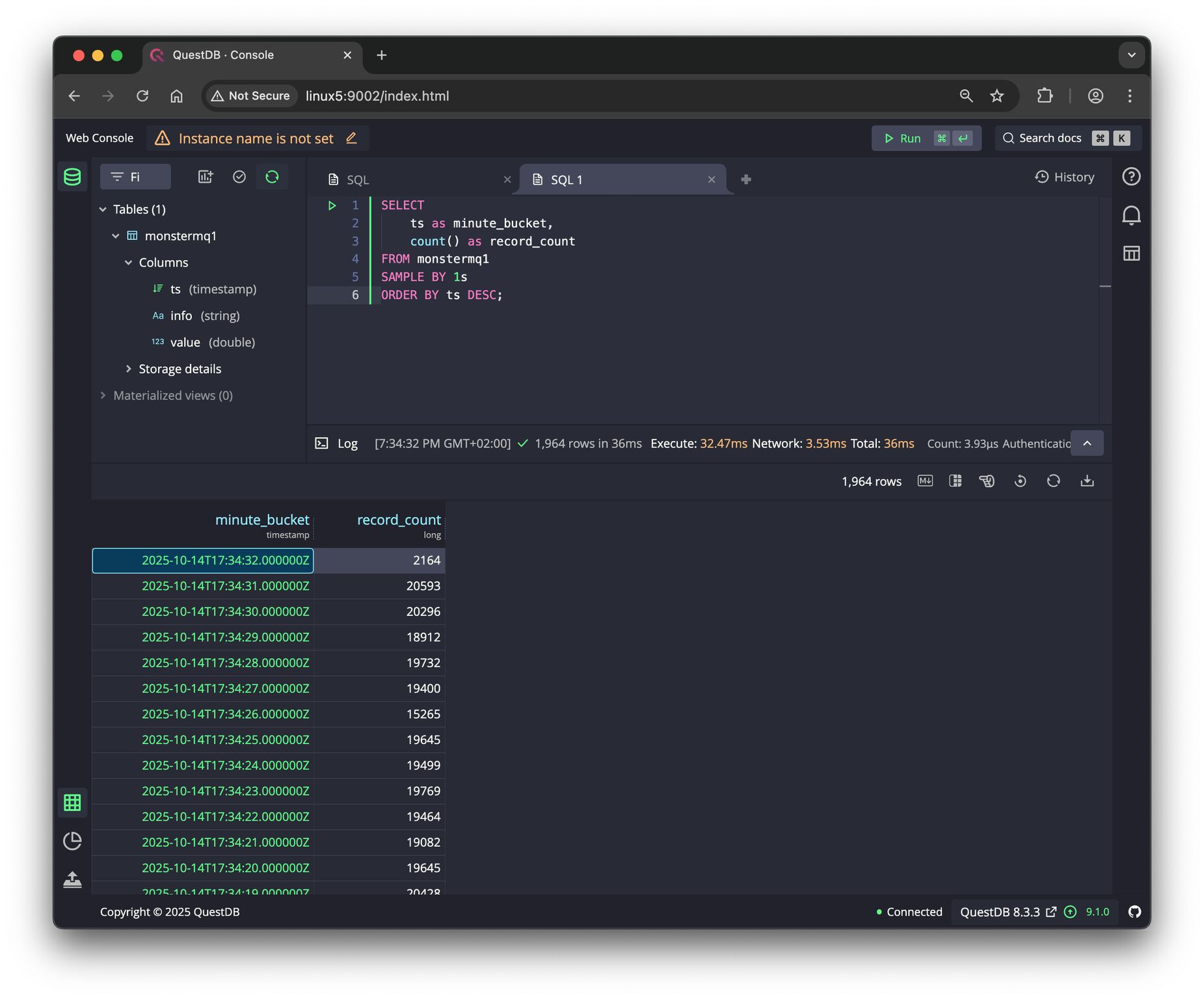
💾 And there is now a JDBC-based Data Logger with store and forward.
It currently supports JSON payloads, with a JSON schema, you can define how fields map to columns in your database tables.
See the pictures, a simple test with 30 Python clients publishing topics to the broker. It stores 20 kHz of data into a QuestDB instance without issues.
It’s a simple way to process and store data where it flows – no need for external services or function frameworks.
👉 MonsterMQ.com 👉 give a star on GitHub if you like it. thx.


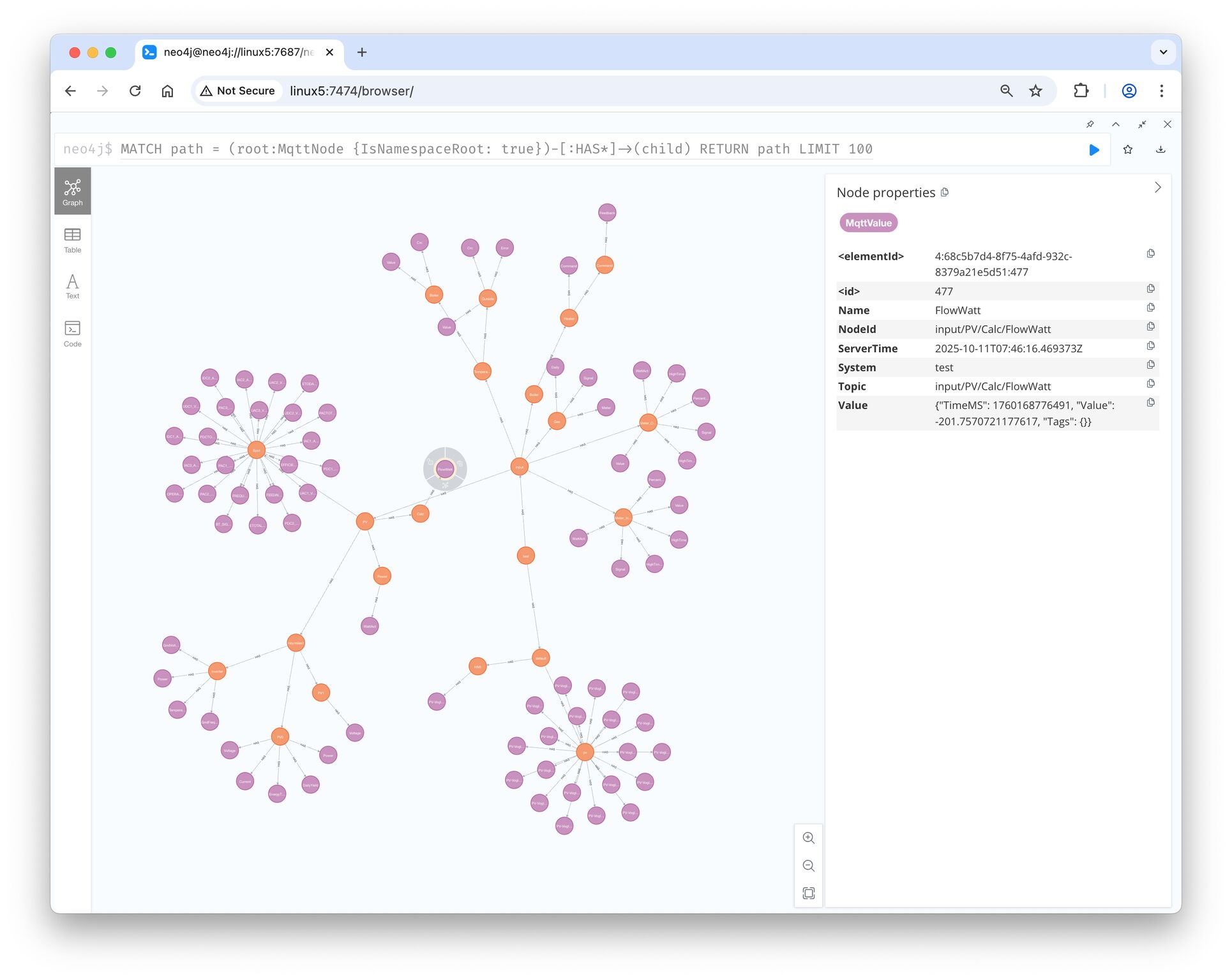
🧌 Weekend Update – MonsterMQ meets Graph Database!
I’ve merged the functionality for bringing MQTT UNS topic trees to Neo4j. Previously part of my Automation-Gateway open source project.
👉 Now, MonsterMQ can push namespaces from the broker into a Neo4j graph database.
💡 Graph databases can help LLMs understand context and relationships better. This integration makes it easy to link your UNS data with other graph data, enriching the context of your factory and process information.
⚠️ But be careful – don’t overload your database with too many writes 😉
👉 MonsterMQ.com 👉 Open-Source!
MonsterMQ ACLs
💬 Yesterday a client asked me:
“Generally, another important element is ACLs — but in a way that I can select topics easier with a GUI instead of using only wildcards, since I need very granular ACLs.”
☕️ I decided to implement it – my date with a lovely woman got canceled today, by her 🤨, so I suddenly had some extra time.
It was straightforward – almost everything in MonsterMQ can be configured through its GraphQL API, so building such a page was easy.
Now, ACL management just got a lot more user-friendly.
⚙️ Next up: I’m working on a lightweight flow engine, so transformations can be implemented directly in the broker – in JavaScript, but still running where the data flows.
👉 MonsterMQ.com
🧩 MonsterMQ – Groundhog Day
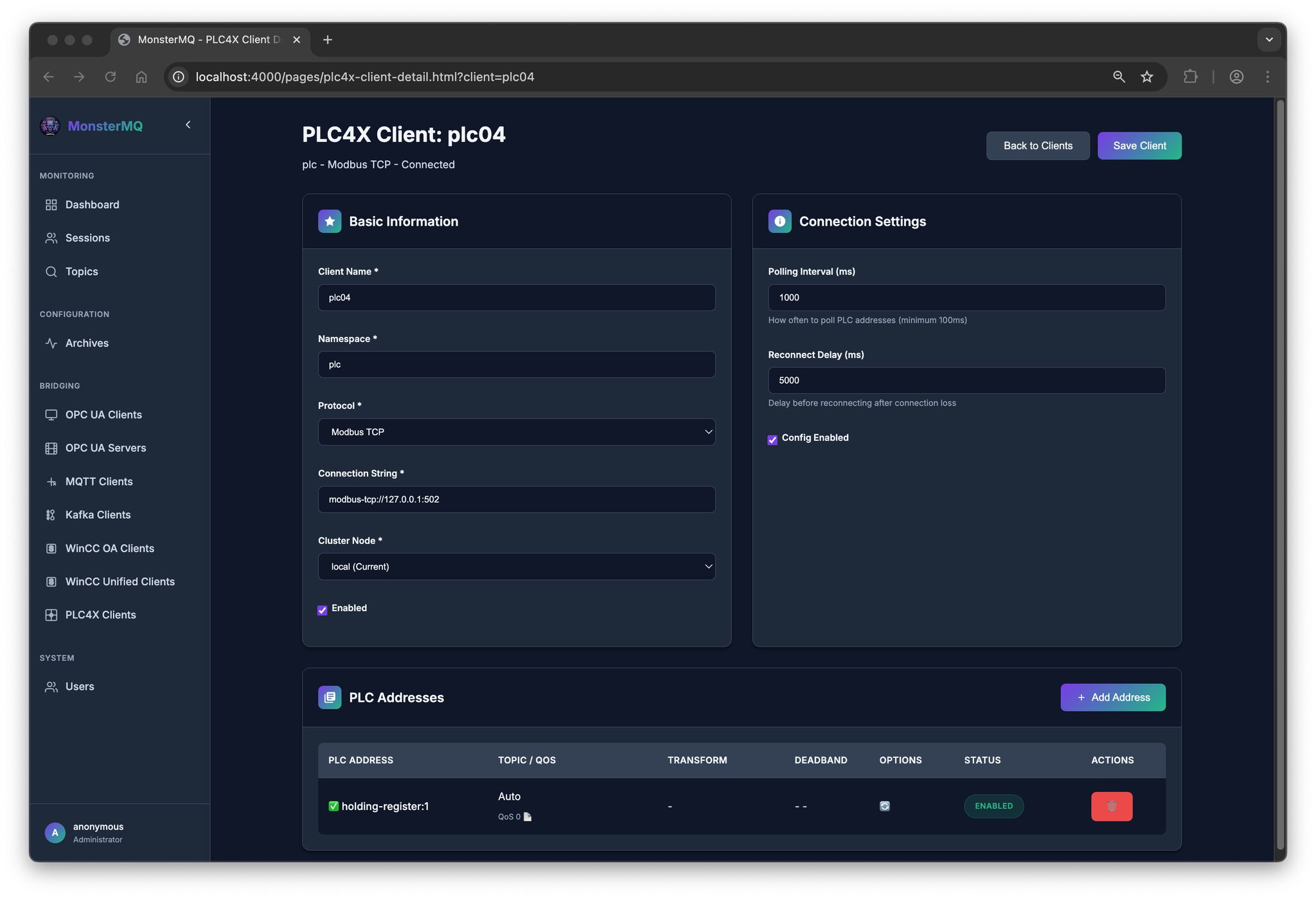
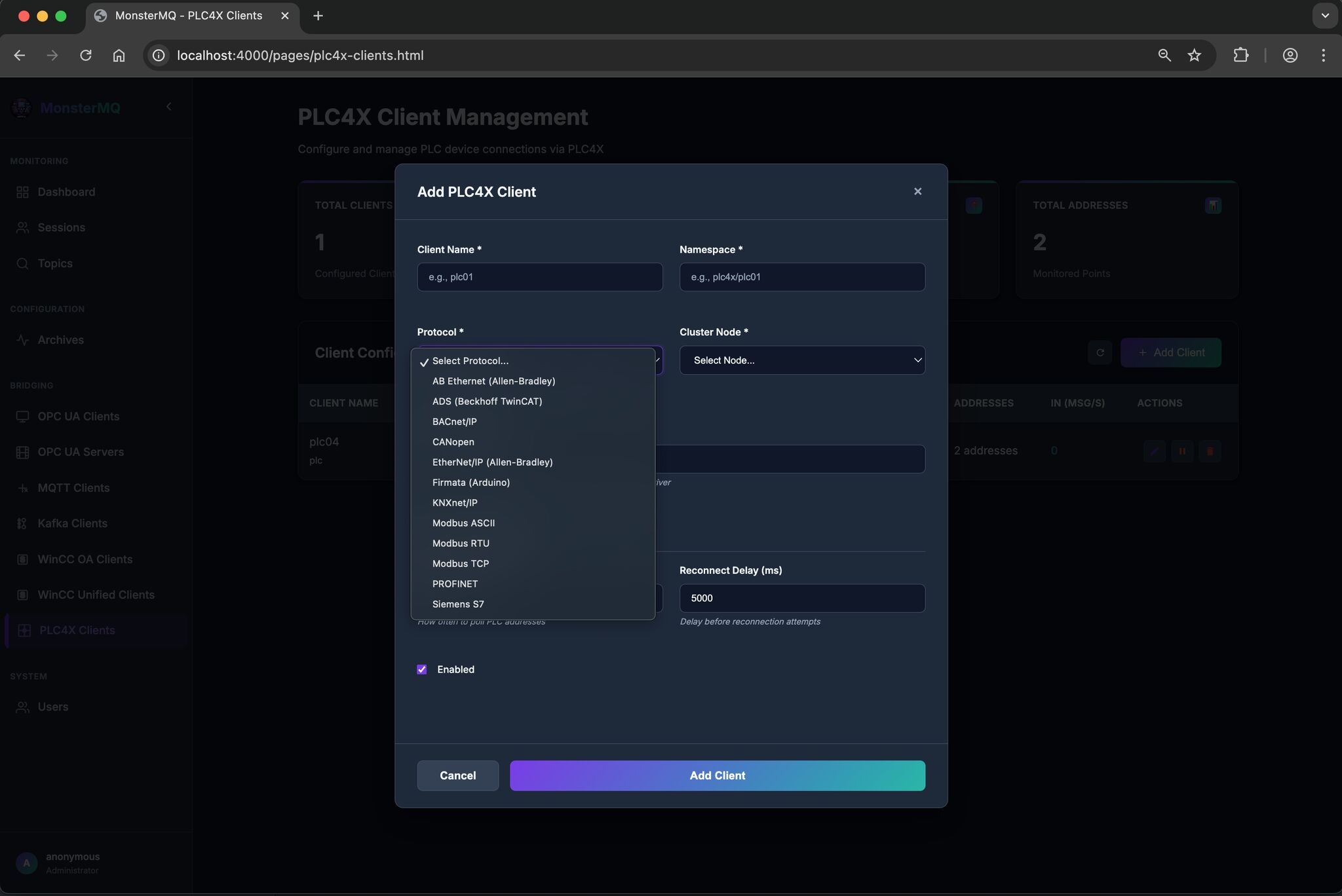
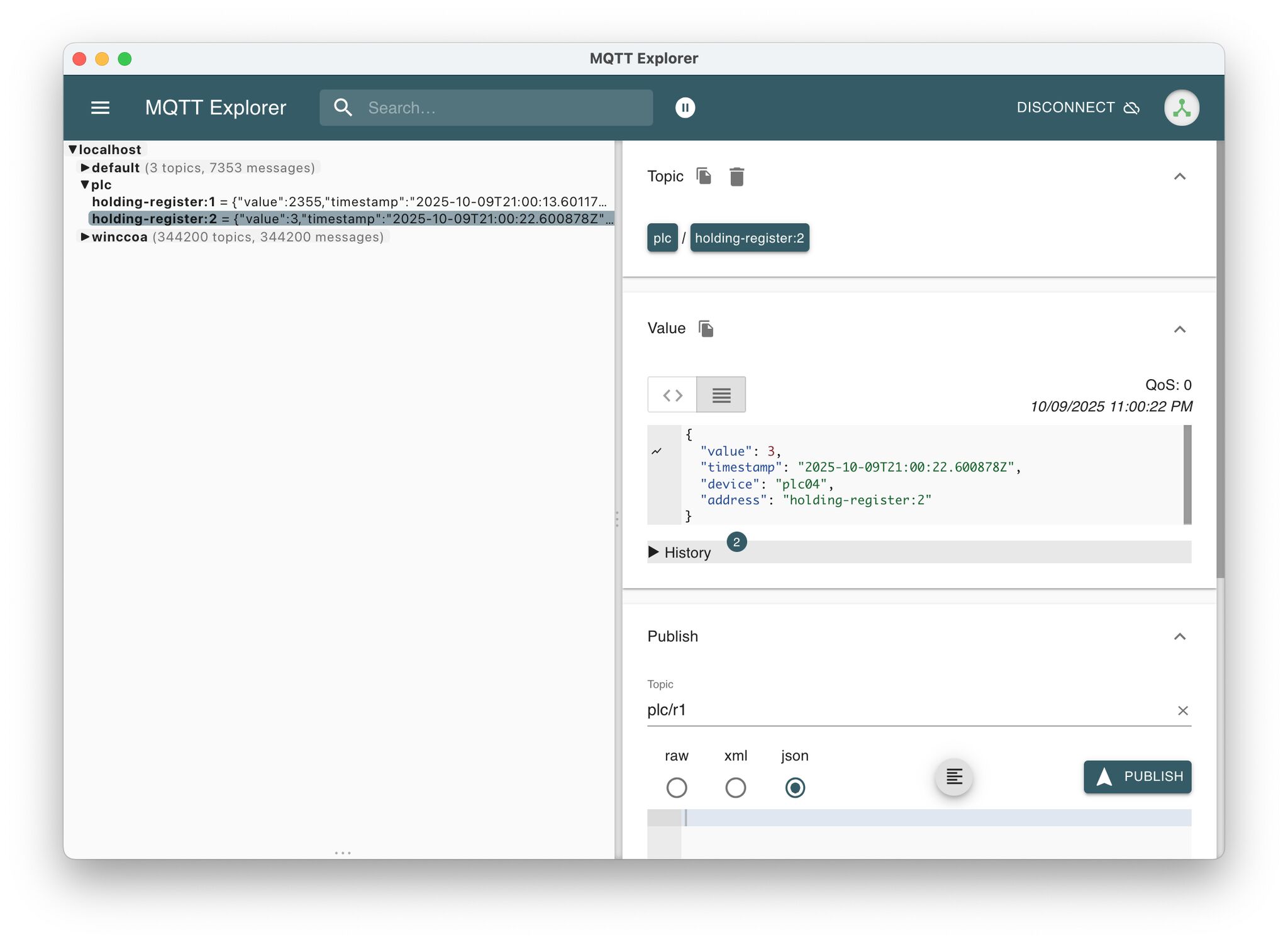
Every day (or night) a new feature – I’ve now added PLC4X
MonsterMQ becomes also a gateway, collecting data from the field to MQTT and can forwarding it to higher layers.
I’ve only tested it with Modbus so far, would be great if others could try it with more PLCs and protocols. See the picture for the list of supported ones.
If you like it, star it on GitHub: MonsterMQ.com
🐉 MonsterMQ – Connecting SCADA to MQTT – Open-Source!
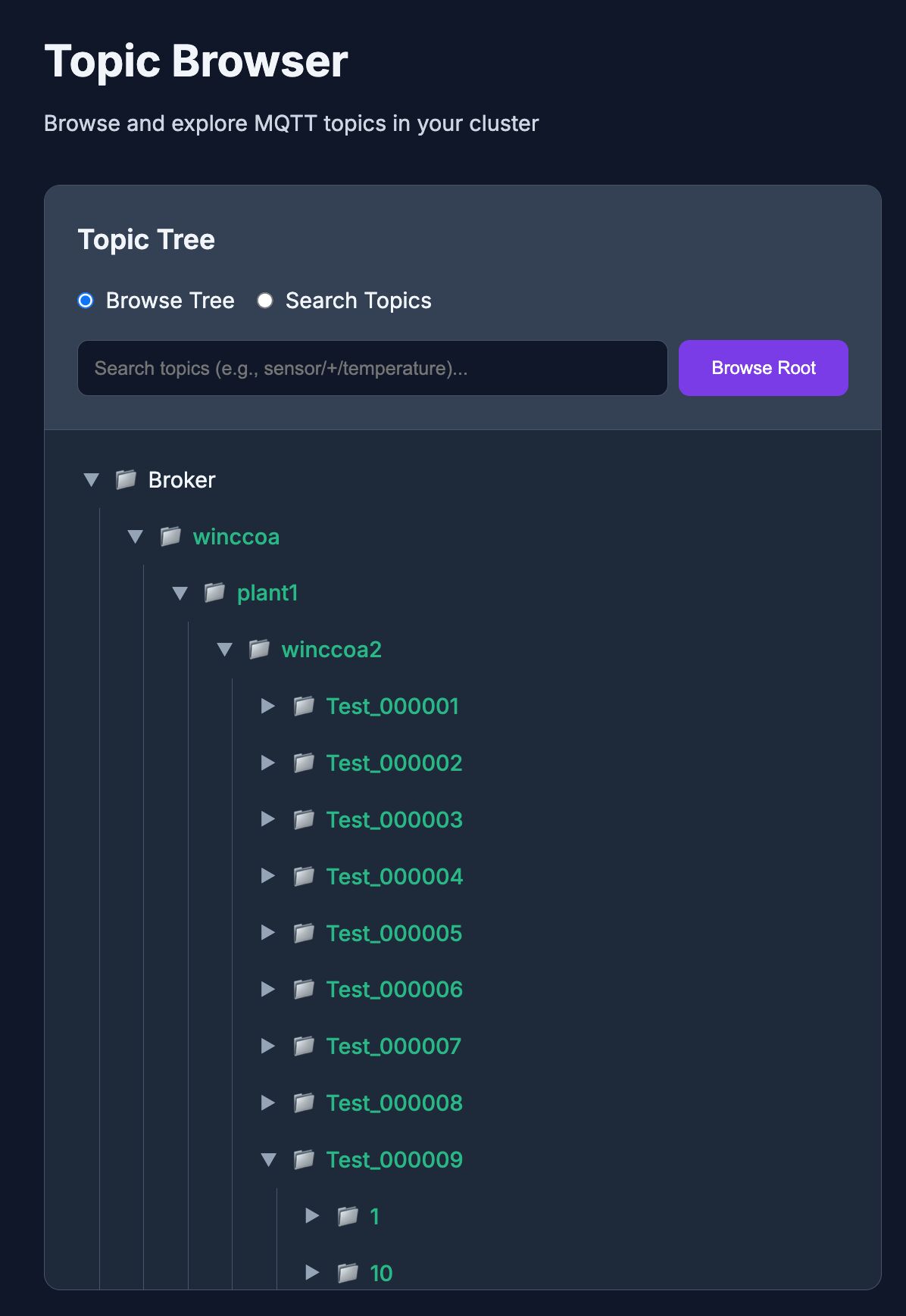
In the newest version, MonsterMQ can now receive tags, events, and alerts directly from WinCC Open Architecture and WinCC Unified.
The broker connects to your SCADA systems and brings the data into MonsterMQ. From there, you can use it however you want, for analytics, dashboards, or integration with other systems.
It can also bring OPC UA data natively into the broker, making it a bridge between the OT and IT worlds.
And if you already have an enterprise MQTT broker, MonsterMQ can act as a gateway, forwarding the data to another broker.
Please star MonsterMQ on GitHub and let me know if some tutorials and videos would be helpful. https://lnkd.in/dqPKFCNQ
🔗 MonsterMQ.com

🚀 MonsterMQ & SIEMENS SCADA… just a teaser…
Currently testing a new connectivity for MonsterMQ.com – bringing WinCC Open Architecture tags into the broker via the WinCC OA GraphQL Server!
It was great to see that with 5,000,000 tags (datapoint elements in OA) and a 40 kHz simulation (40,000 value changes per second!), a single WinCC OA GraphQL Server can easily handle that load via GraphQL Subscriptions — even on commodity hardware! 💪
🤨 Why not publish the tags from WinCC OA with its MQTT capabilities? Because the MQTT protocol doesn’t support bulk messages, it’s not efficient for transferring a large number of topic value changes.
💡And I am using WinCC OA’s great continuous SQL queries, which makes it possible to subscribe to 5 Millions tags with just a single SQL query.
MonsterMQ.com will soon get a bridge to WinCC OA 🥳 Stay tuned. And WinCC Unified will be next 😀
Weekend is over 👉 New version of MonsterMQ 🧌
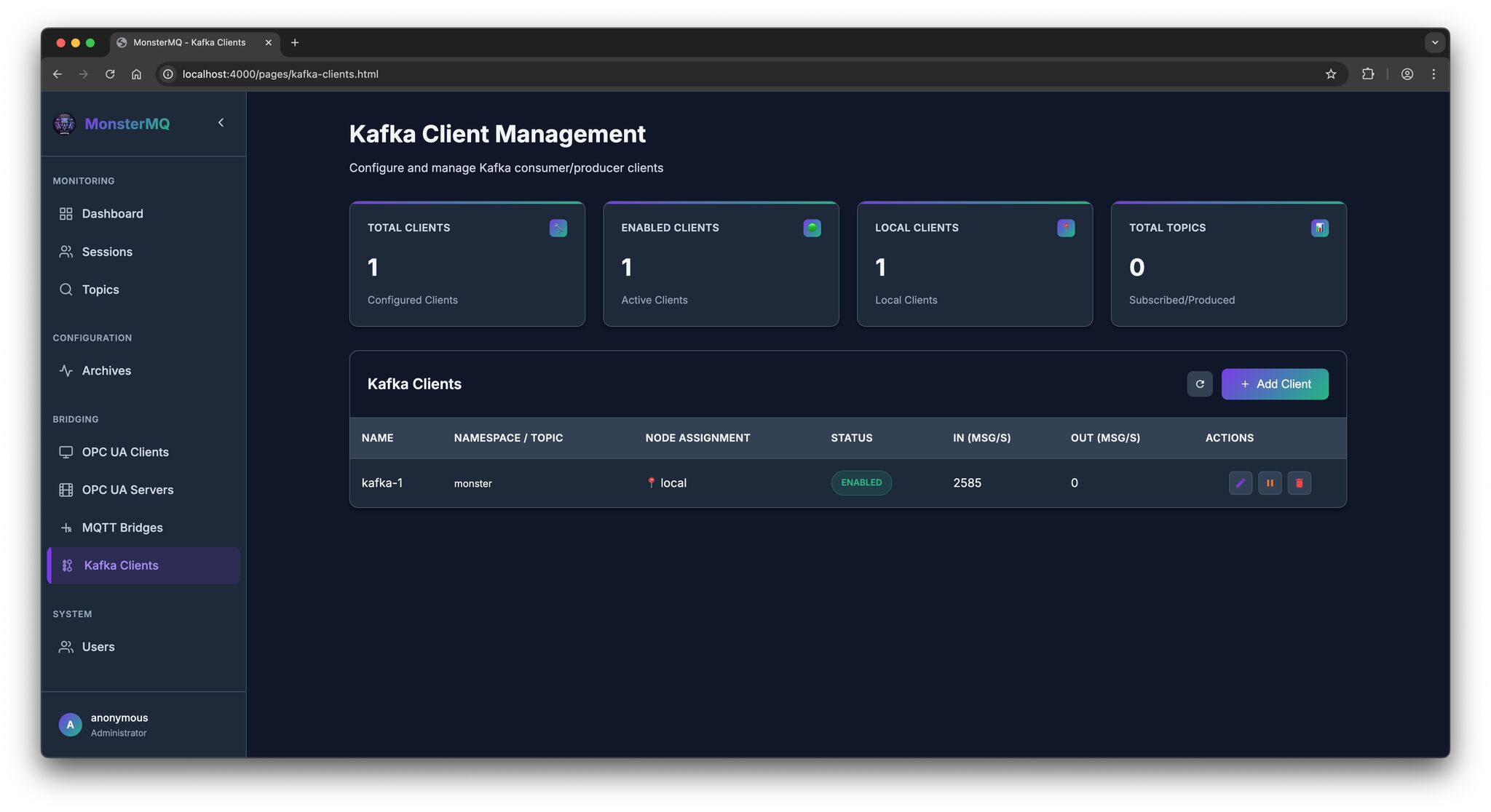
🚨 Breaking News: We’ve added Kafka Client functionality!
It acts as a consumer, enabling data replication from one MQTT Broker instance to another, together with the Kafka Archiving – using a fast, reliable, and bandwidth-optimized Kafka protocol and broker.
👉 Sending data from local MQTT brokers to the cloud is much more efficient by using Kafka.
And this release brings also some more improvements! We’ve reworked metric handling:
👉 Metrics are now shown as values per second
👉 Added metrics for OPC UA Client, OPC UA Server, and MQTT Bridges, Archiving (to databases).
MonsterMQ.com


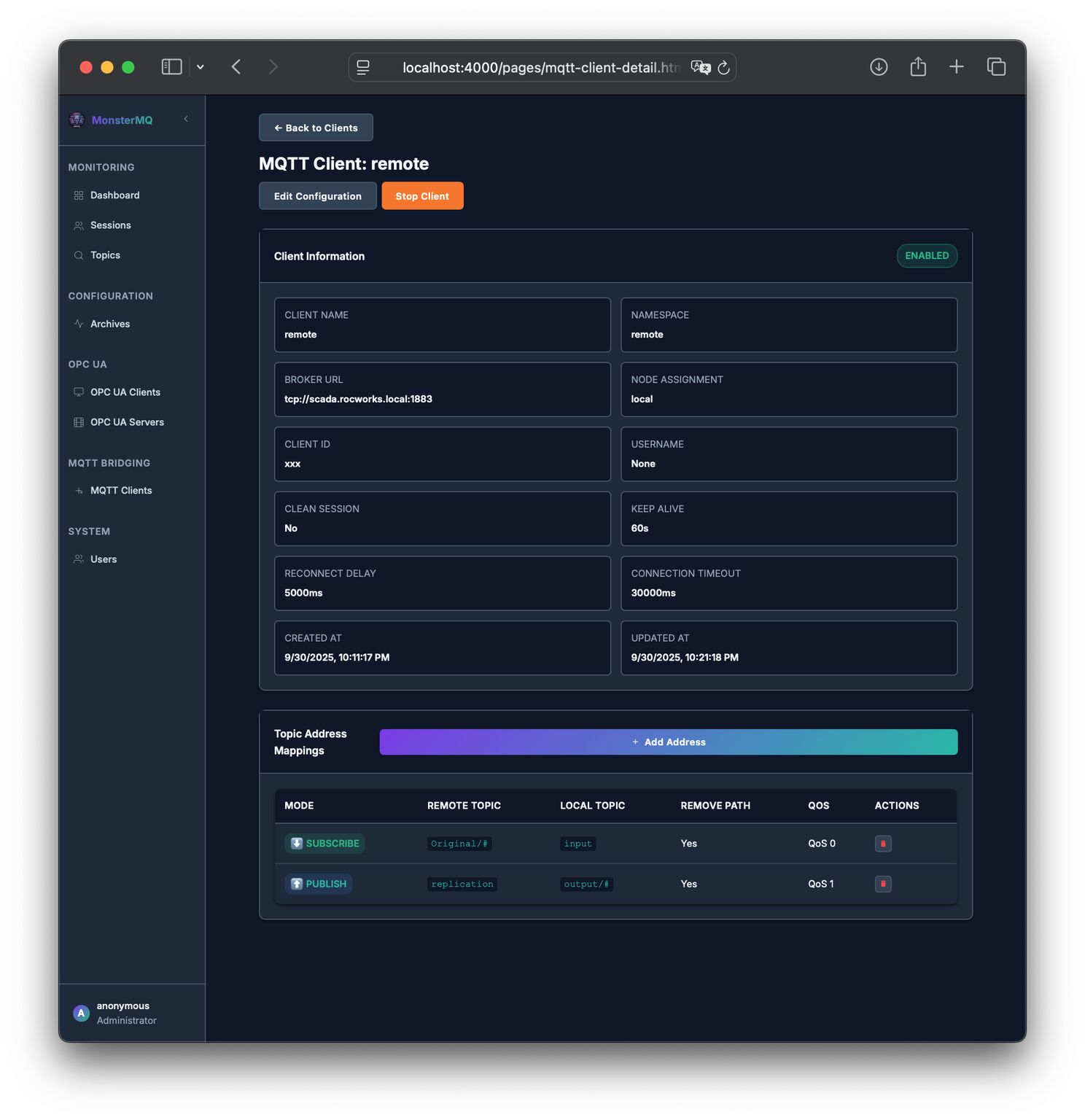
🚀 Again a MonsterMQ Update: MQTT-to-MQTT Replication
You can:
👉 Connect to other brokers and publish local topics to the remote one
👉 Subscribe to remote topics and bring them into your local broker
💡 Both directions work with wildcards
This makes it easier to link brokers across sites, clouds, or edge setups.
And after this update… we’ll take a short break 😉 even though I already have more ideas for features…
Please give a ⭐️ on GitHub if you like the project!
Open-Source 🔗 MonsterMQ.com