In this tutorial, I will guide you through the essential steps to set up the Automation Gateway, harness the power of YAML extensions in Visual Studio Code for configuration, and connect various devices, including OPC UA, MQTT, and PLC4X devices. I will show how to integrate the values from the devices to the Gateway’s OPC UA server and how to use the MQTT interface to get the values from the devices via a MQTT client. Additionally values from the connected devices will be logged to a Influx database.
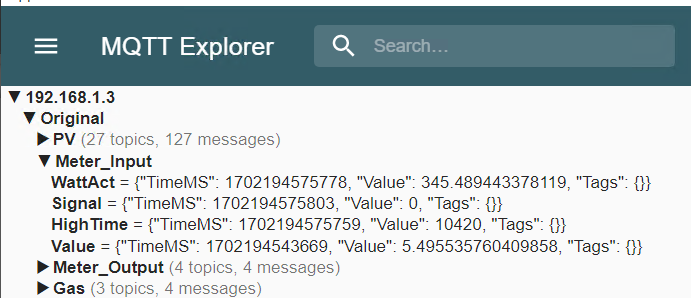
I wanted to get my Home-Automation values to SCADA, it’s a “self-made” JSON message format. I tried it with Ignition and the MQTT Module. Btw.: it’s great that they have the Makers Edition for non-commercial use at home 👍. But I don’t know why, it only got one topic and one value from my MQTT Broker, and it did not receive any updates. Don’t know what went wrong…
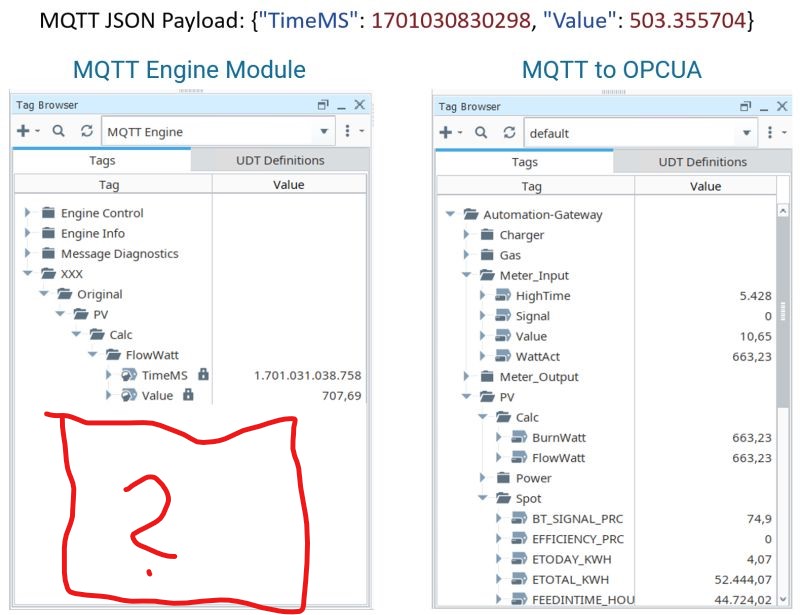
Anyhow, I decided to add a custom JSON format to the Automation-Gateway.com. It’s simple, just define the JSON-Path to the value and optionally to a timestamp in milliseconds since epoch or to an ISO 8601 format.
Now I can use the Automation-Gateway’s OPC UA server in any SCADA system to visualize my MQTT values…
Here is the config.yaml configuration file for the Automation-Gateway.
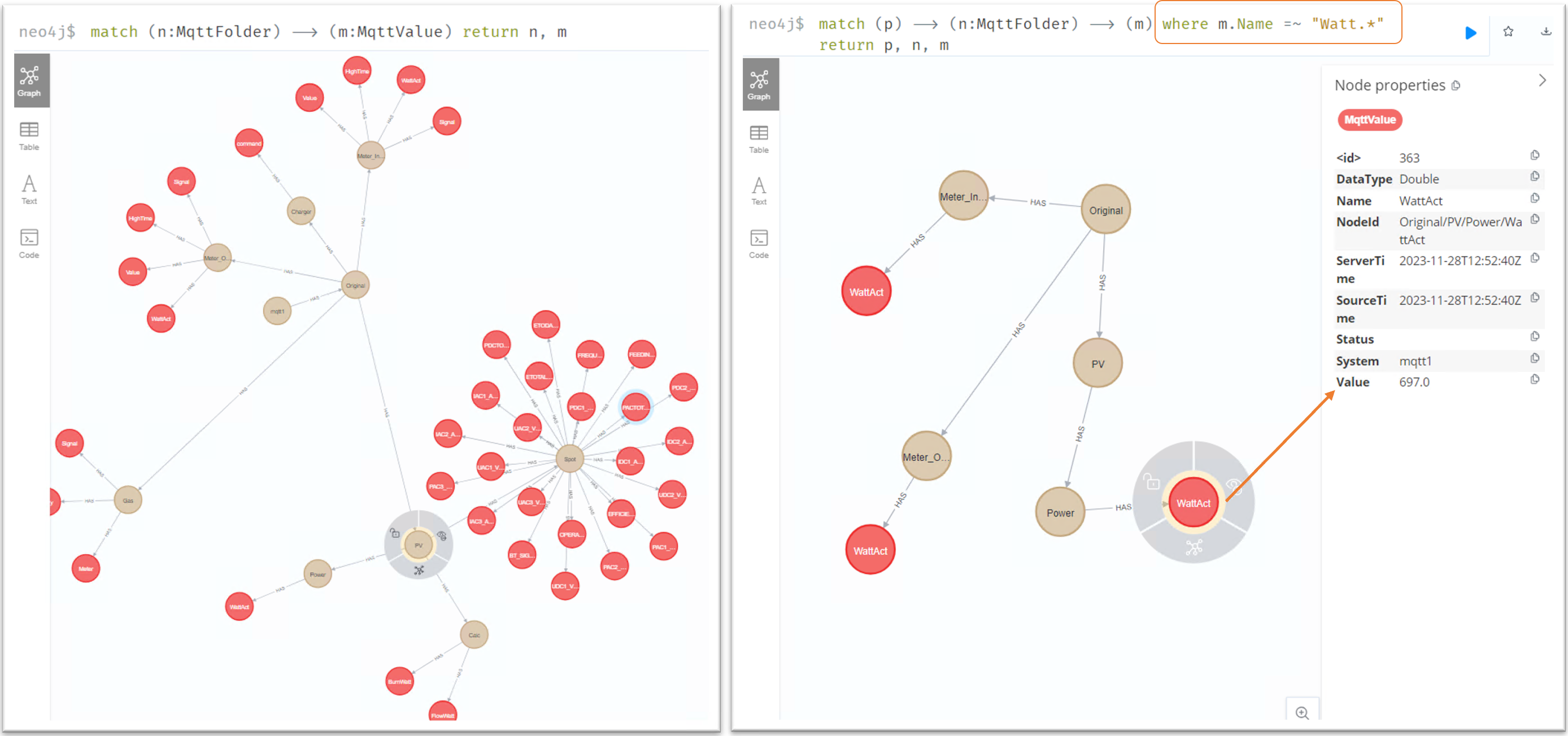
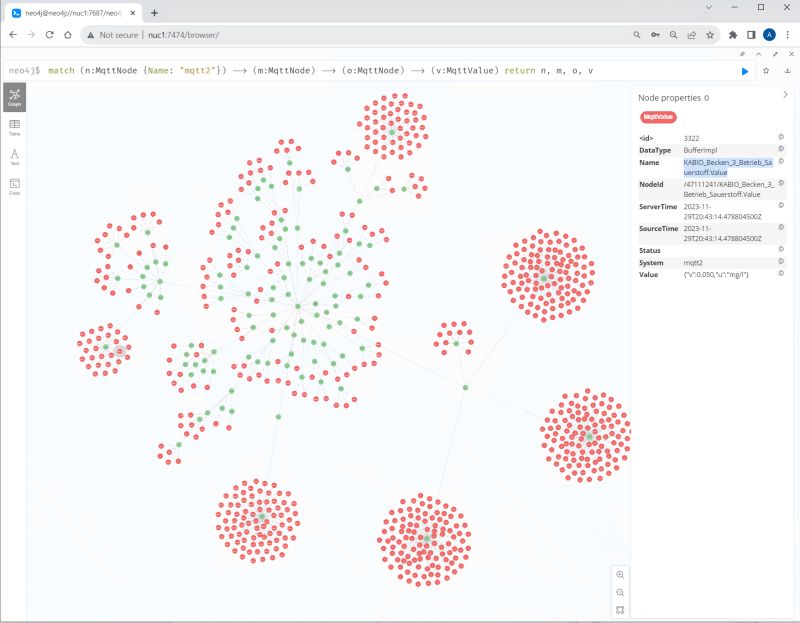
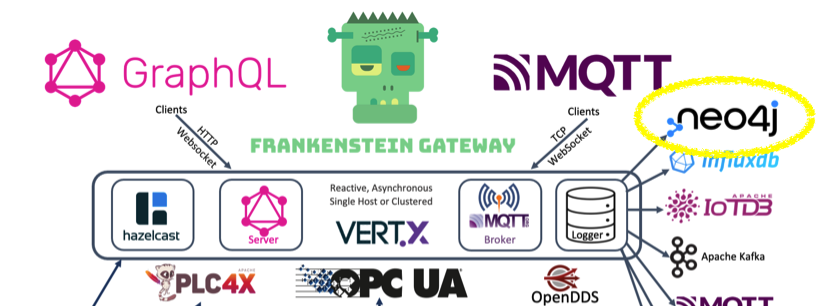
🤔 I thought about if it could make sense to connect to a MQTT broker and write the topic-path in a structured and connected way to a graph database. It could reflect a companies UNS with ISA structure in a graph with query possibilities.
🤝 The UNS could be enriched by adding additional meta information to the database and be linked to the MQTT nodes. Graph queries could be used to combine the enriched data with the current values of the machines…
👉 I reactivated the Neo4J Logger in the Automation-Gateway.com, and enabled MQTT for it. It creates the nodes in a neo4j graph database based on the incoming MQTT messages.
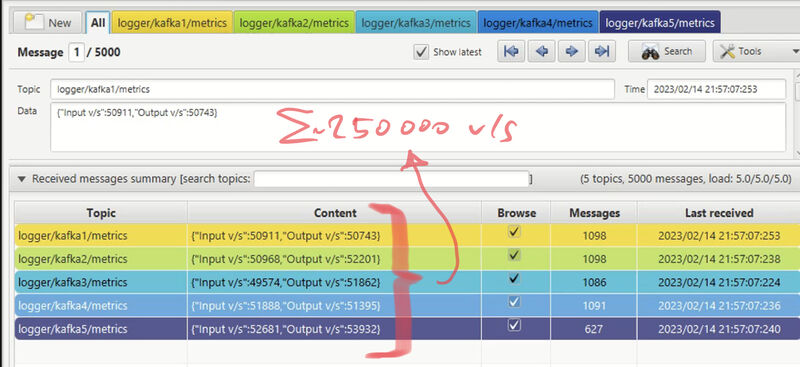
Did a test with one gateway and collected 250000 😲 value changes per second(!) from 10 OPC UA servers and wrote it to 10 topics on a single Kafka Broker… Kafka was bored 😴… one and a half core of an i7 PC. The gateway had a lot of work to do, collect and bulk all the single values and then send it to Kafka … roughly 10 cores of an i7 PC.
The gateway has a GraphQL and MQTT interface where you can read and write OPC UA values. On an internal MQTT topic the logger publishes how many values are getting in and out…
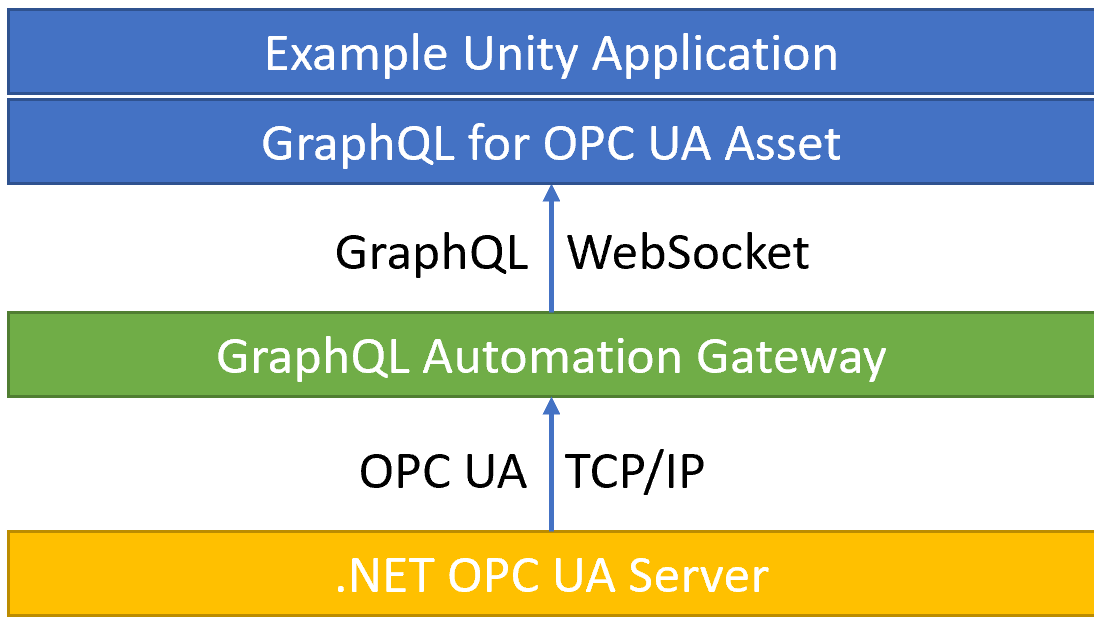
In a simple setup I have tested to send 2000 value changes per second from an OPC UA server to Unity with GraphQL, the Open-Source Frankenstein Automation Gateway, and the GraphQL for Unity Asset. And it could go up to 10000 value changes per second…
I had one DotNet OPC UA server with a lot of simulated tags with random data. The .Net OPC UA server is the DotNet reference implementation from the OPCFoundation, which can be found here.
On top of that the Open-Source Frankenstein Automation Gateway for GraphQL was running. It is connected to the OPC UA server. It offers a GraphQL interface to the tags of one or more connected OPC UA servers.
In Unity I had used the GraphQL for OPC UA Asset to easily connect to the Gateway, browse the tags, and subscribe to the value changes of 100 tags.
Each tag was changed by the OPC UA server every 45ms. This ends up in a bit more than 2000 value changes per seconds, which were sent from the OPC UA server to the Unity Application.
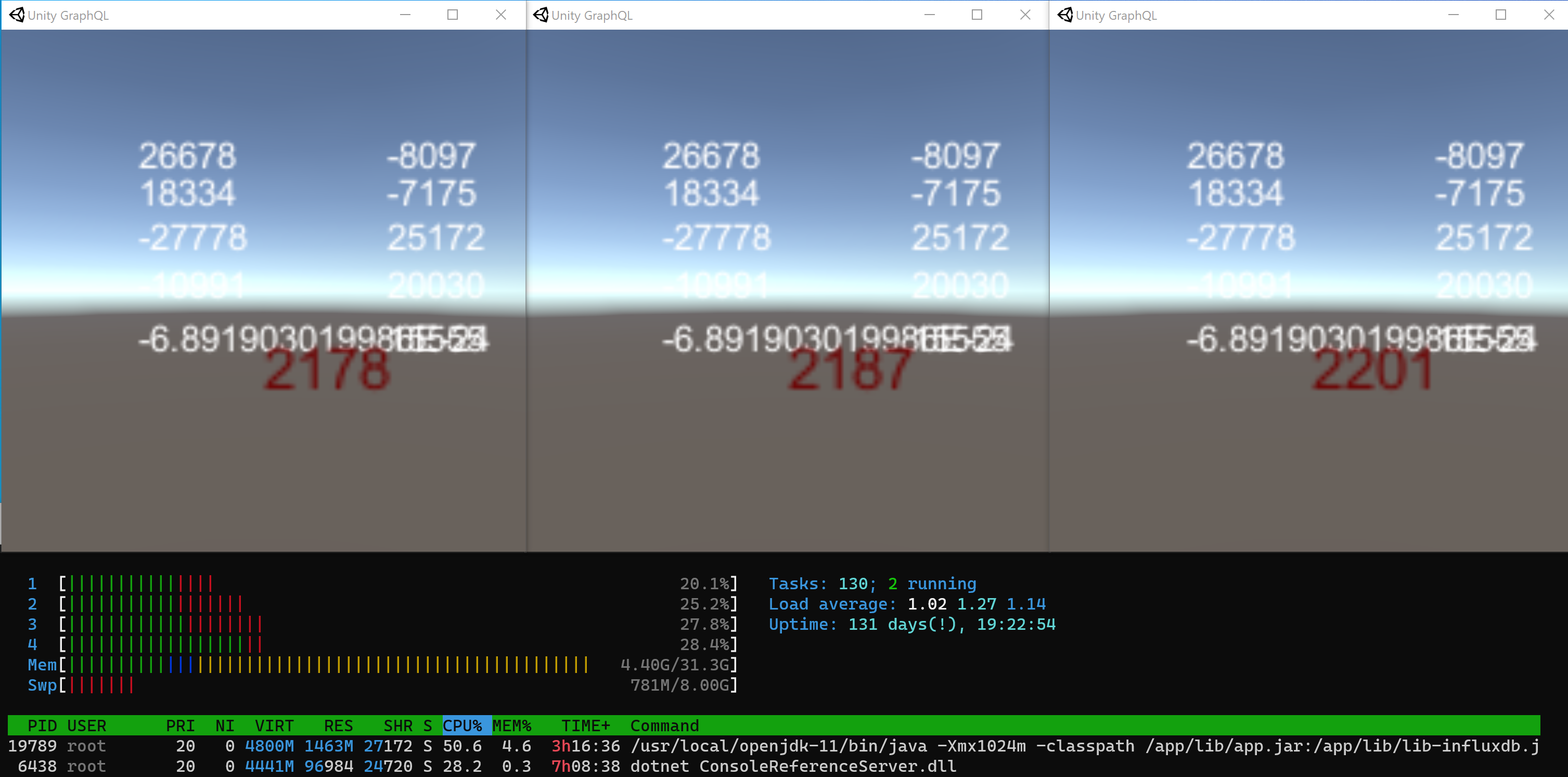
Here we see the Application running 3 times on my Laptop with an Intel(R) Core(TM) i7-9850H CPU @ 2.60GHz. In the center you see the amount of incoming value changes per second (red number). Around that number, we see some of the values coming in from OPC UA. At the bottom we see the CPU load of the Frankenstein Automation Gateway (java program) and the OPC UA DotNet Server. Both were running on an old Intel(R) Core(TM) i3-6100U CPU @ 2.30GHz.
It was also possible to increase to load up to 10000 value changes per seconds! Sending 100 values every 10ms from OPC UA to Unity…
At startup it can also write the OPC UA node structure into the graph database, so that the basic model of the OPC UA server is mirrored to the graph database. For that you have to add the “Schemas” section in the config file (see an example configuration file below). There you can choose which RootNodes (and all sub nodes) of your OPC UA systems should be mirrored to the graph database.
Once you have the (simplified) OPC UA information model in the graph database, you can add on top of that your own knowledge graph data and create relations to OPC UA nodes of your machines to enrich the semantic data of the OPC UA model.
With that model you can leverage the power of your Knowledge Graphs in combination with live data from your machines and use Cypher queries to get the knowledge out of the graph.
Here we see an example of the OPC UA server from the SCADA System WinCC Open Architecture. The first level of nodes below the “Objects” node represent Datapoint-Types (e.g. PUMP1) followed by the Datapoint-Instances (e.g.: PumpNr) and below that we see the datapoint elements (e.g. value => speed). An datapoint element is an OPC UA variable where we also see the current value from the SCADA system.
Example Gateway configuration file:
Database:
Logger:
- Id: neo4j
Enabled: true
Type: Neo4j
Url: bolt://nuc1.rocworks.local:7687
Username: "neo4j"
Password: "manager"
Schemas:
- System: opc1 # Replicate node structure to the graph database
RootNodes:
- "ns=2;s=Demo" # This node and everything below this node
- System: winccoa1 # Replicate the nodes starting from "i=85" (Objects) node
WriteParameters:
BlockSize: 1000
Logging:
- Topic: opc/opc1/path/Objects/Demo/SimulationMass/SimulationMass_Float/+
- Topic: opc/opc1/path/Objects/Demo/SimulationMass/SimulationMass_Double/+
- Topic: opc/opc1/path/Objects/Demo/SimulationMass/SimulationMass_Int16/+
- Topic: opc/winccoa1/path/Objects/PUMP1/#
- Topic: opc/winccoa1/path/Objects/ExampleDP_Int/#
Here is a simple HTML page which fetches data from the OPC UA Automation Gateway “Frankenstein”. It uses HTTP and simple GraphQL queries to fetch the data from the Automation Gateway and display it with Google Gauges. It is very simple and it is periodically polling the data. GraphQL can also handle subscription, but then you need to setup a Websocket connection.
<html>
<head>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<script type="text/javascript">
google.charts.load('current', {'packages':['gauge']});
google.charts.setOnLoadCallback(drawChart);
var data = null
var options = null
var chart = null
function drawChart() {
data = google.visualization.arrayToDataTable([
['Label', 'Value'],
['Tank 1', 0],
['Tank 2', 0],
['Tank 3', 0],
]);
options = {
width: 1000, height: 400,
redFrom: 90, redTo: 100,
yellowFrom: 75, yellowTo: 90,
minorTicks: 5
};
chart = new google.visualization.Gauge(document.getElementById('chart_div'));
chart.draw(data, options);
}
function refresh() {
const request = new XMLHttpRequest();
const url ='http://localhost:4000/graphql';
request.open("POST", url, true);
request.setRequestHeader("Content-Type", "application/json");
request_data = {
"query": `{
Systems {
unified1 {
HmiRuntime {
HMI_RT_5 {
Tags {
Tank1_Level { Value { Value } }
Tank2_Level { Value { Value } }
Tank3_Level { Value { Value } }
}
}
}
}
}
}`
}
request.send(JSON.stringify(request_data));
request.onreadystatechange = function() {
if (this.readyState==4 /* DONE */ && this.status==200) {
const result = JSON.parse(request.responseText).data
const x = result.Systems
data.setValue(0, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank1_Level.Value.Value);
data.setValue(1, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank2_Level.Value.Value);
data.setValue(2, 1, x.unified1.HmiRuntime.HMI_RT_5.Tags.Tank3_Level.Value.Value);
chart.draw(data, options);
}
}
}
setInterval(refresh, 250)
</script>
</head>
<body>
<div id="chart_div" style="width: 400px; height: 120px;"></div>
<!--<button name="refresh" onclick="refresh()">Refresh</button>-->
</body>
</html>
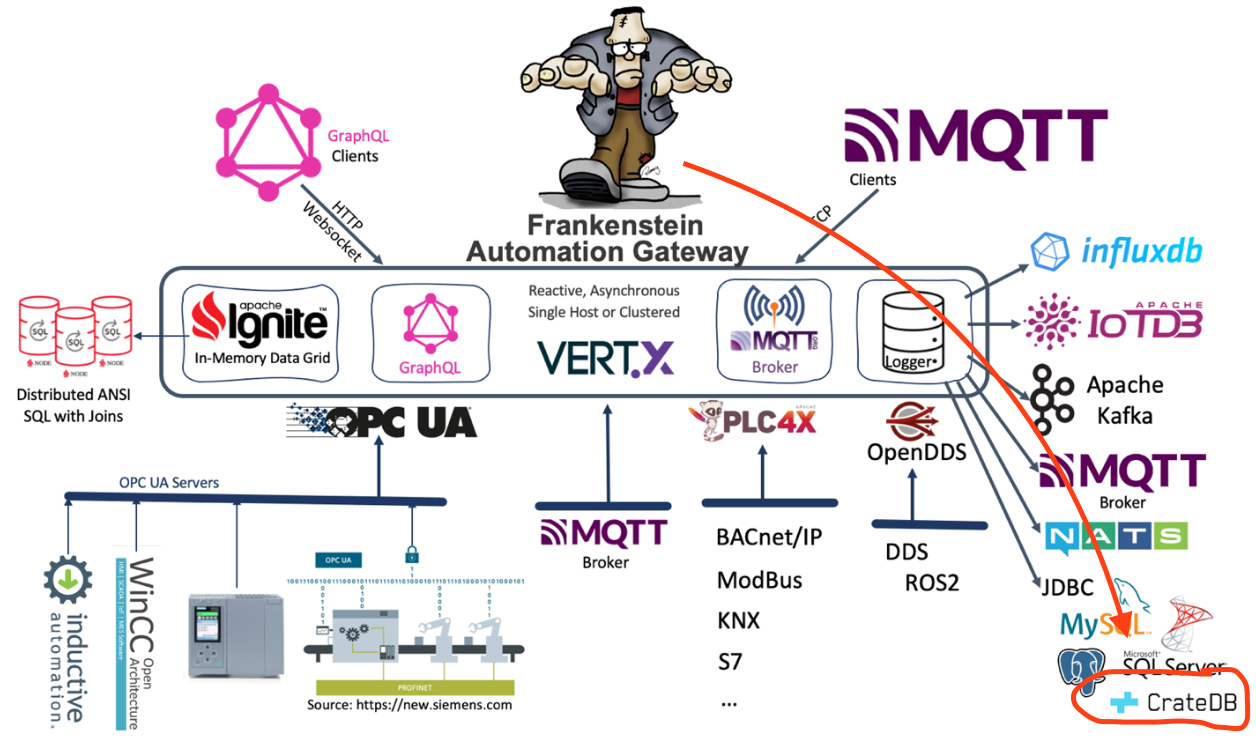
Really like Crate.io … based on Elasticsearch, but with #SQL interface and optimised for time series. Now also added to Frankenstein for #opcua tag logging…
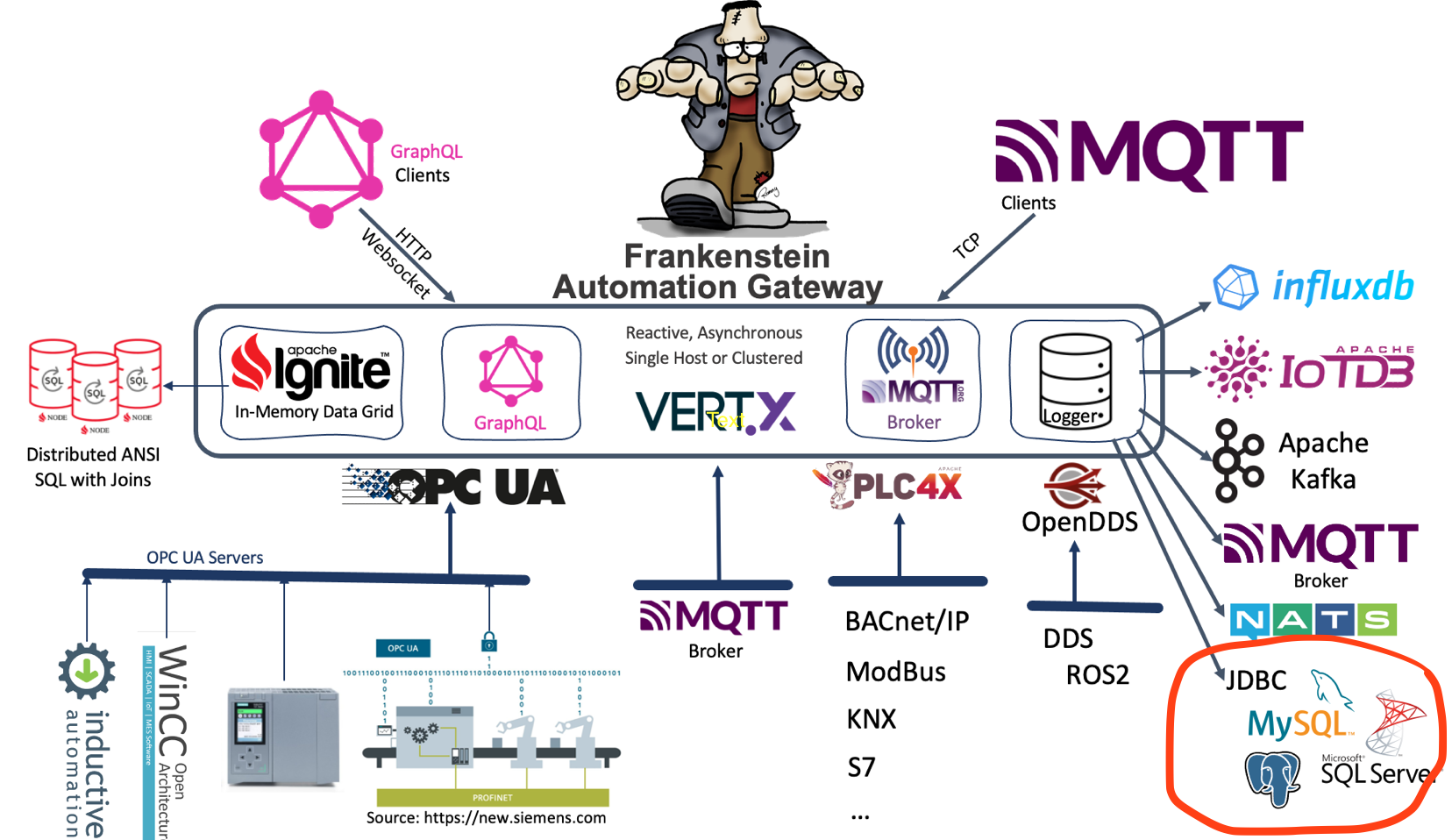
Added #JDBC as logging option to the Open-Source Automation-Gateway Frankenstein. Values from #OPCUA servers can now also be logged to relational databases – #sql is still so great and powerful! Tested with #postgresql#mysql and #mssqlserver … fetching history values via the integrated #graphql server is also included…
You have to add the JDBC driver to your classpath and set the appropriate JDBC URL path in the Frankenstein configuration file – see an example below. PostgreSQL, MySQL and Microsoft SQL Server JDBC drivers are already included in the build.gradle file (see lib-jdbc/build.gradle) and also appropriate SQL statements are implemented for those relational databases. If you use other JDBC drivers you can add the driver to the lib-jdbc/build.gradle file as runtime only dependency and you may specify SQL statements for insert and select in the configuration file.
You can specify the table name in the config file with the option “SqlTableName”, if you do not specify the table name then “events” will be used as default name.
Create a table with this structure. For PostgreSQL, MySQL and Microsoft SQL Server the table will be created on startup automatically.
CREATE TABLE IF NOT EXISTS public.events
(
sys character varying(30) NOT NULL,
nodeid character varying(30) NOT NULL,
sourcetime timestamp without time zone NOT NULL,
servertime timestamp without time zone NOT NULL,
numericvalue numeric,
stringvalue text,
status character varying(30) ,
CONSTRAINT pk_events PRIMARY KEY (system, nodeid, sourcetime)
)
TABLESPACE ts_scada;