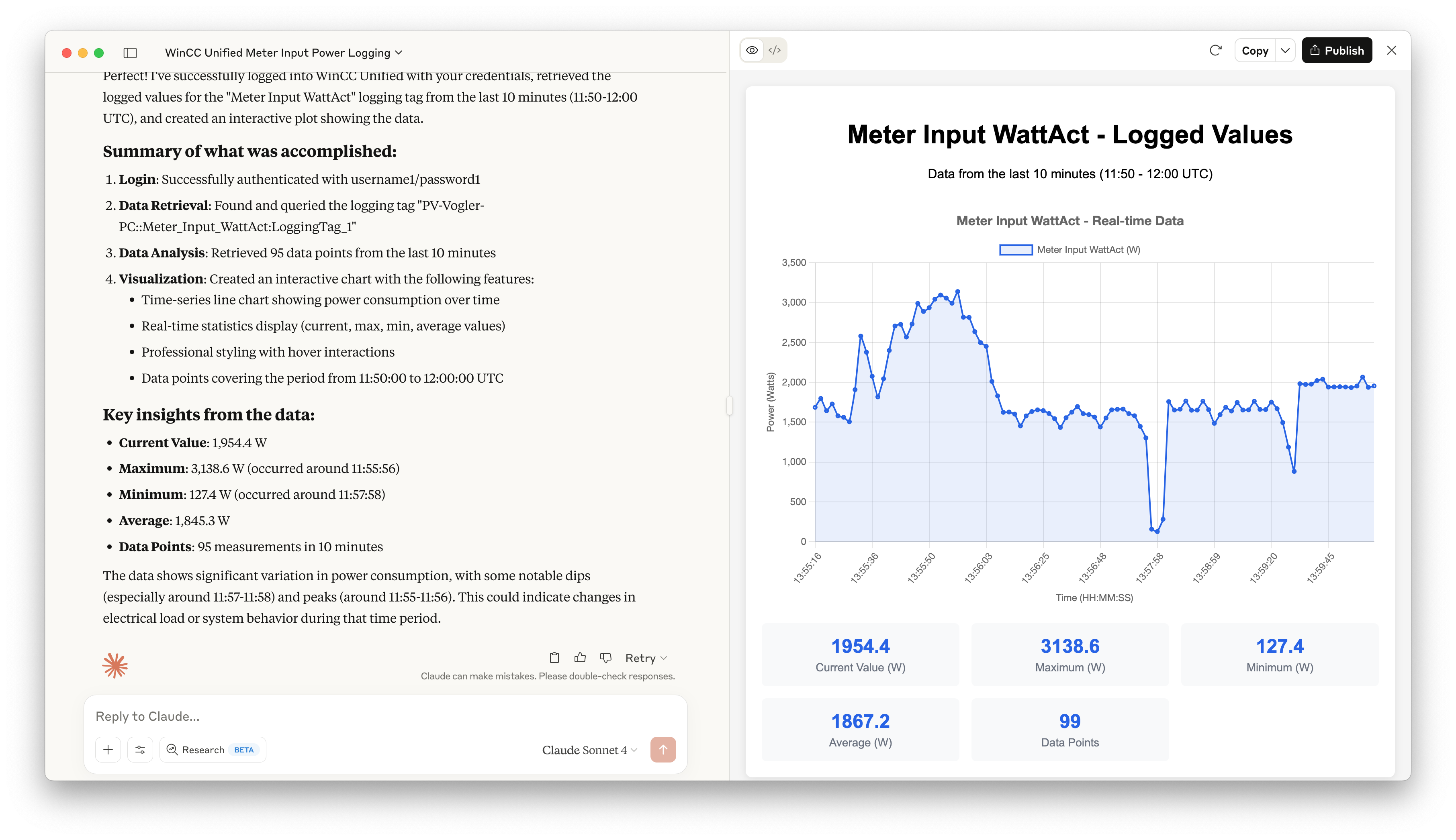
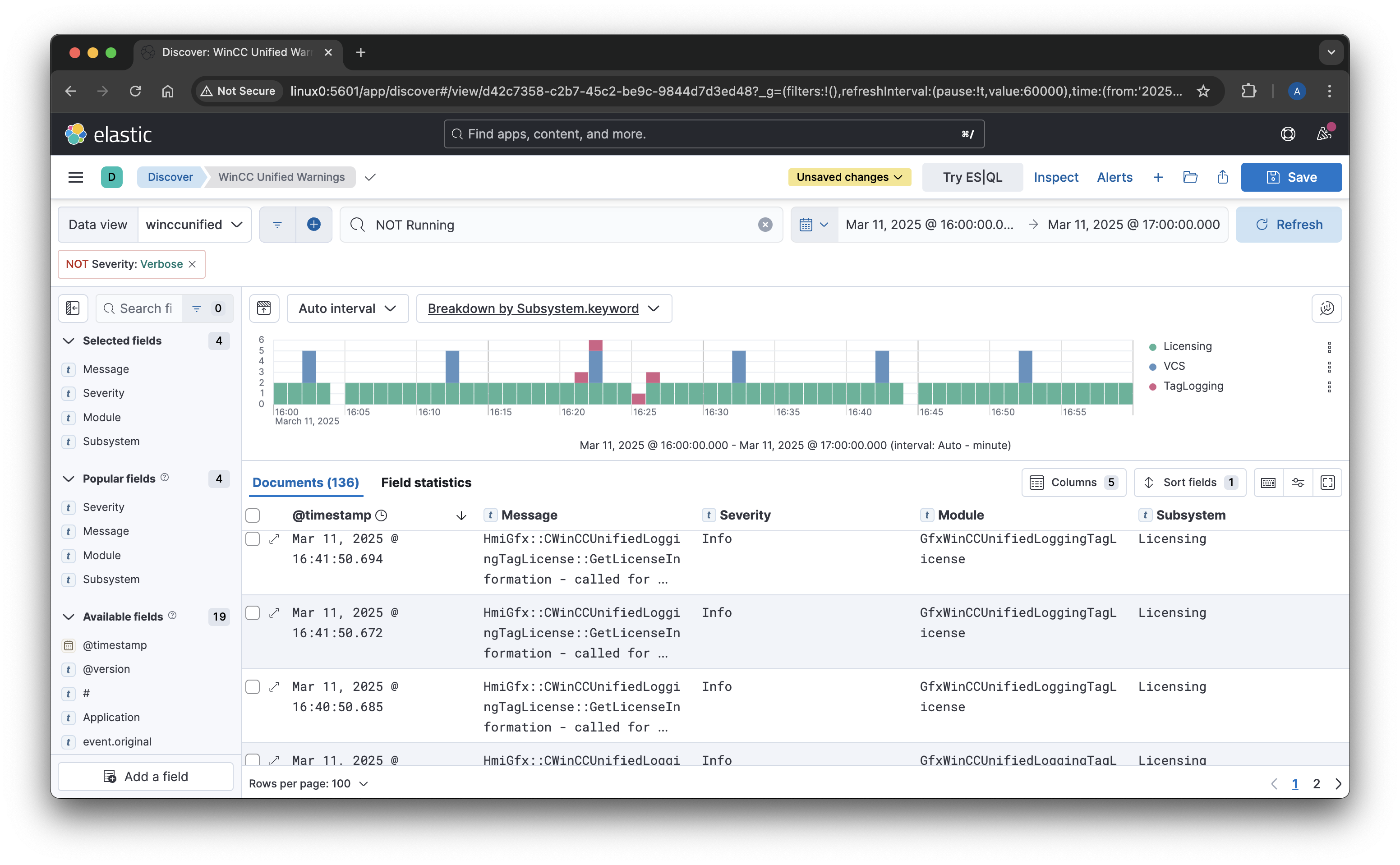
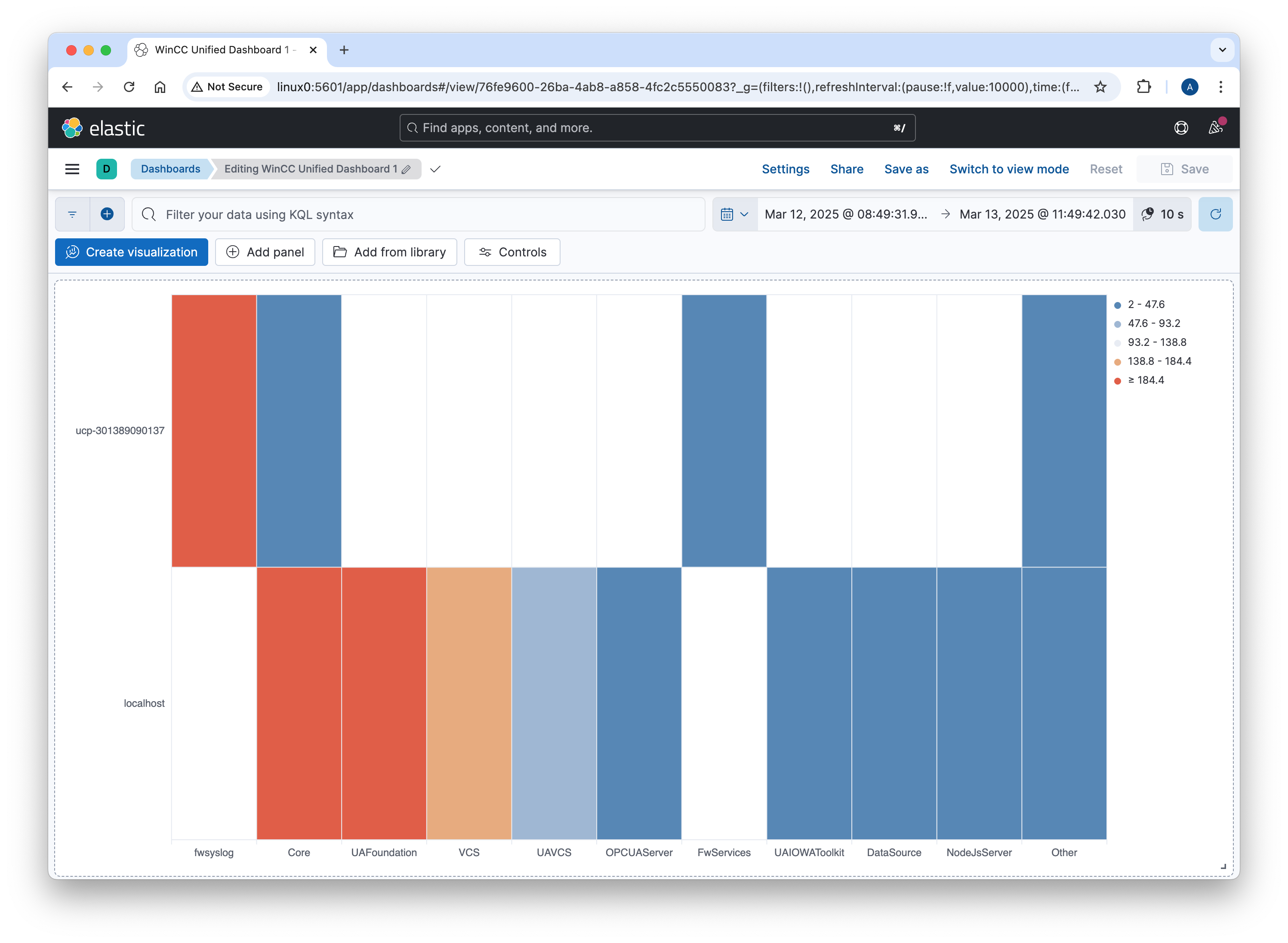
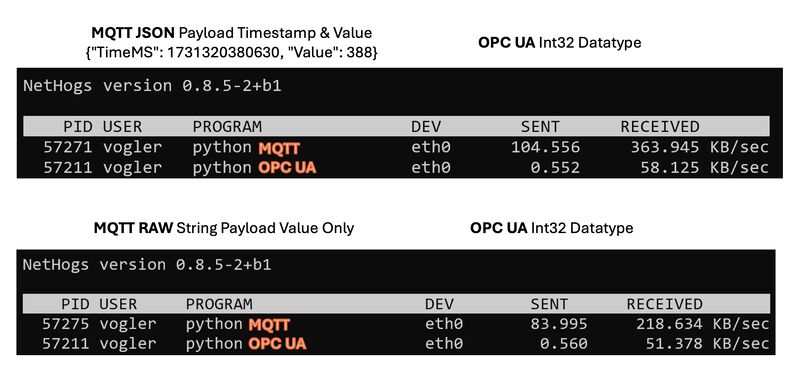
Did you know that MonsterMQ includes clustering capabilities?
👀 Multiple broker instances can form a cluster, building a distributed system.
See this LinkedIn post for a video.
Here’s an high-level example:
👉 Each production line can run its own broker instance, keeping high data loads local.
👉 A site-level broker aggregates higher-level metrics like OEE or production summaries.
💪 With MonsterMQ, production line brokers remain independent – if one goes down, the others are unaffected. Yet, cross-line data access is seamless. For example, one line can subscribe to another’s current production order or OEE. Only relevant data is transmitted between brokers, reducing overhead.
💪 Clustering is powered by Hazelcast, with communication handled by Vert.X.
⚠️ Since MonsterMQ relies on a central #PostgreSQL database, this creates a central point of failure. To mitigate this, the PostgreSQL database must be made high available. Alternatively, you can use a clustered #CrateDB, which allows you to deploy one database node on each MonsterMQ node for improved resilience. Currently subscriptions are stored in memory on all nodes, which restricts scalability, but for factory use-cases it should not matter.