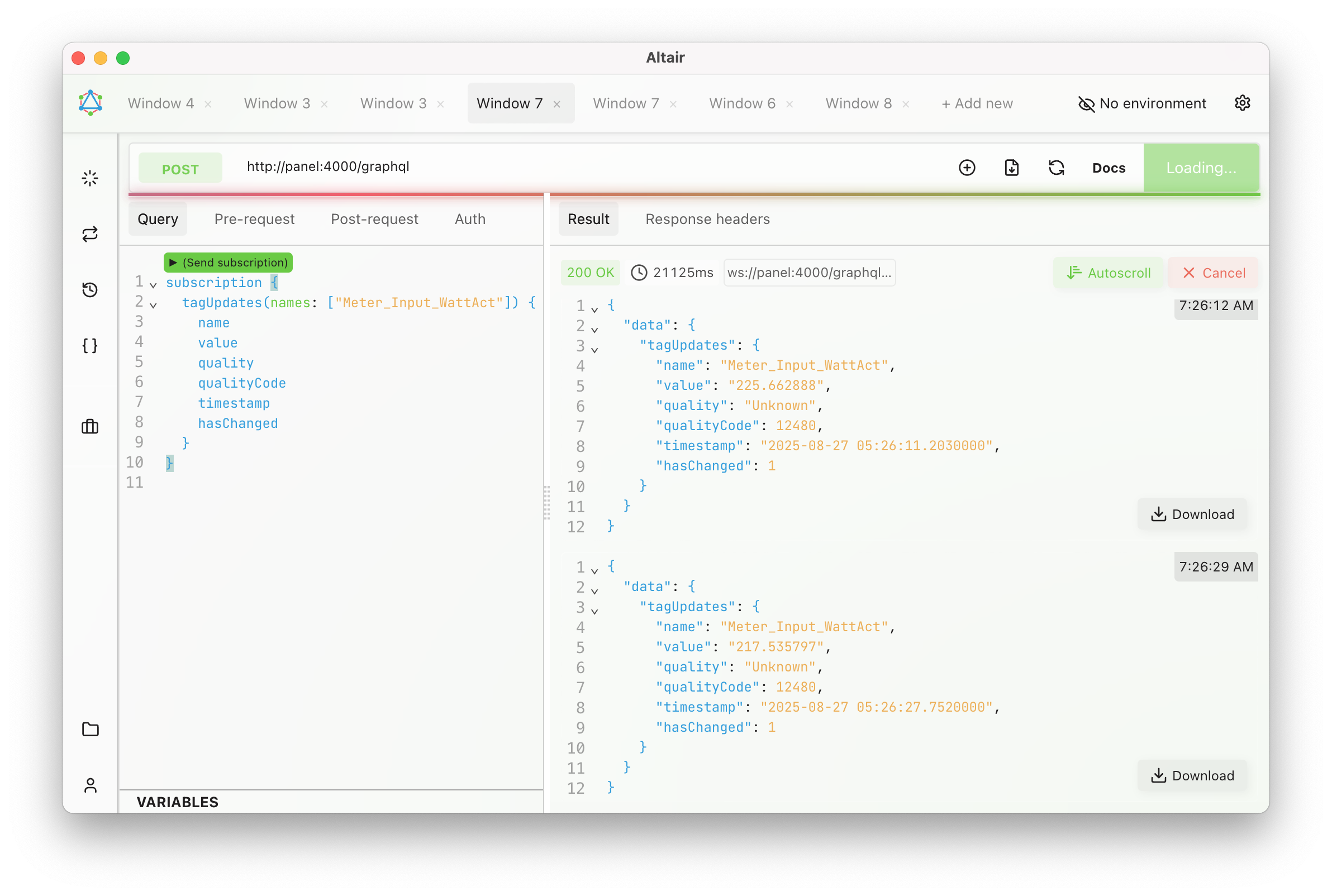
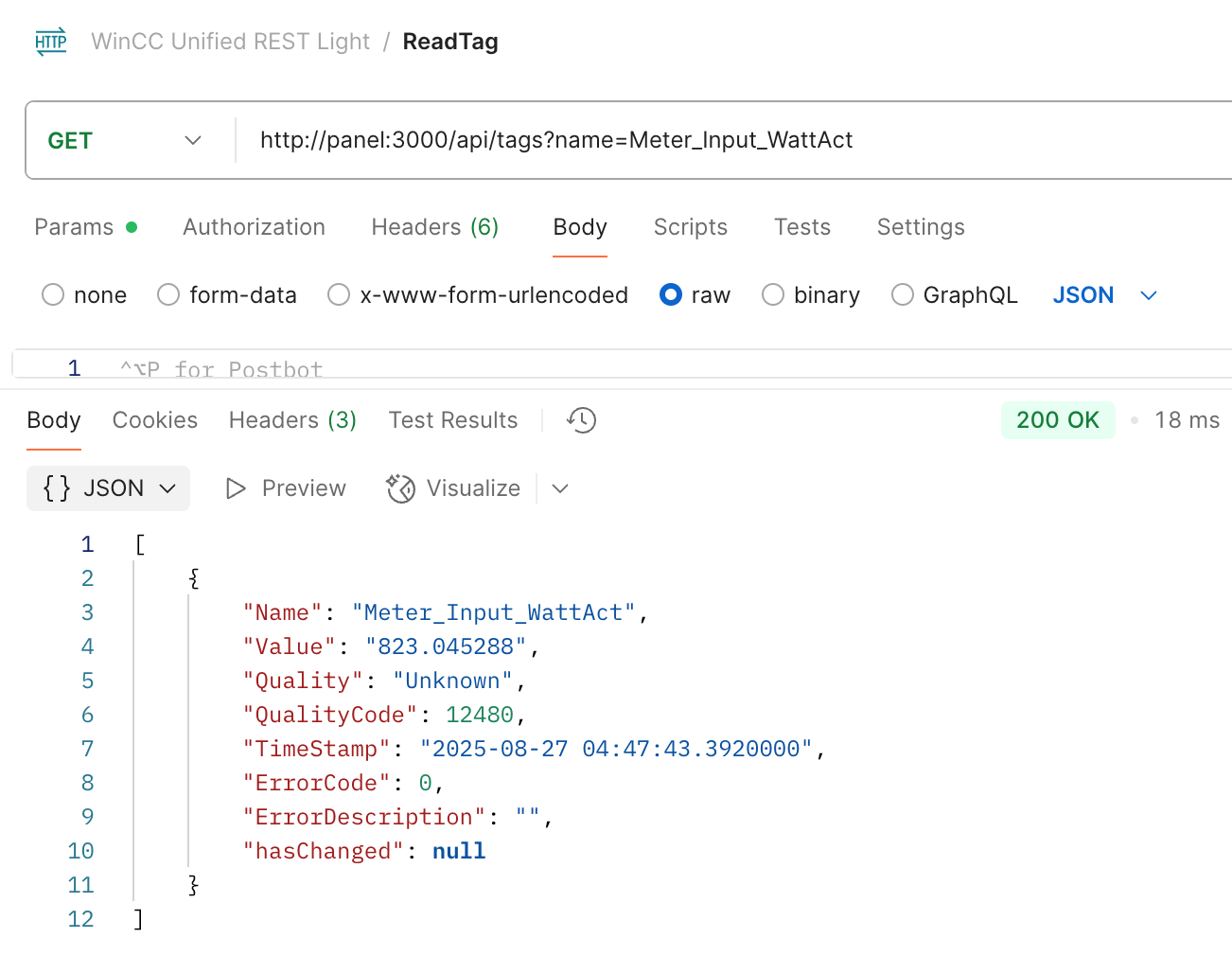
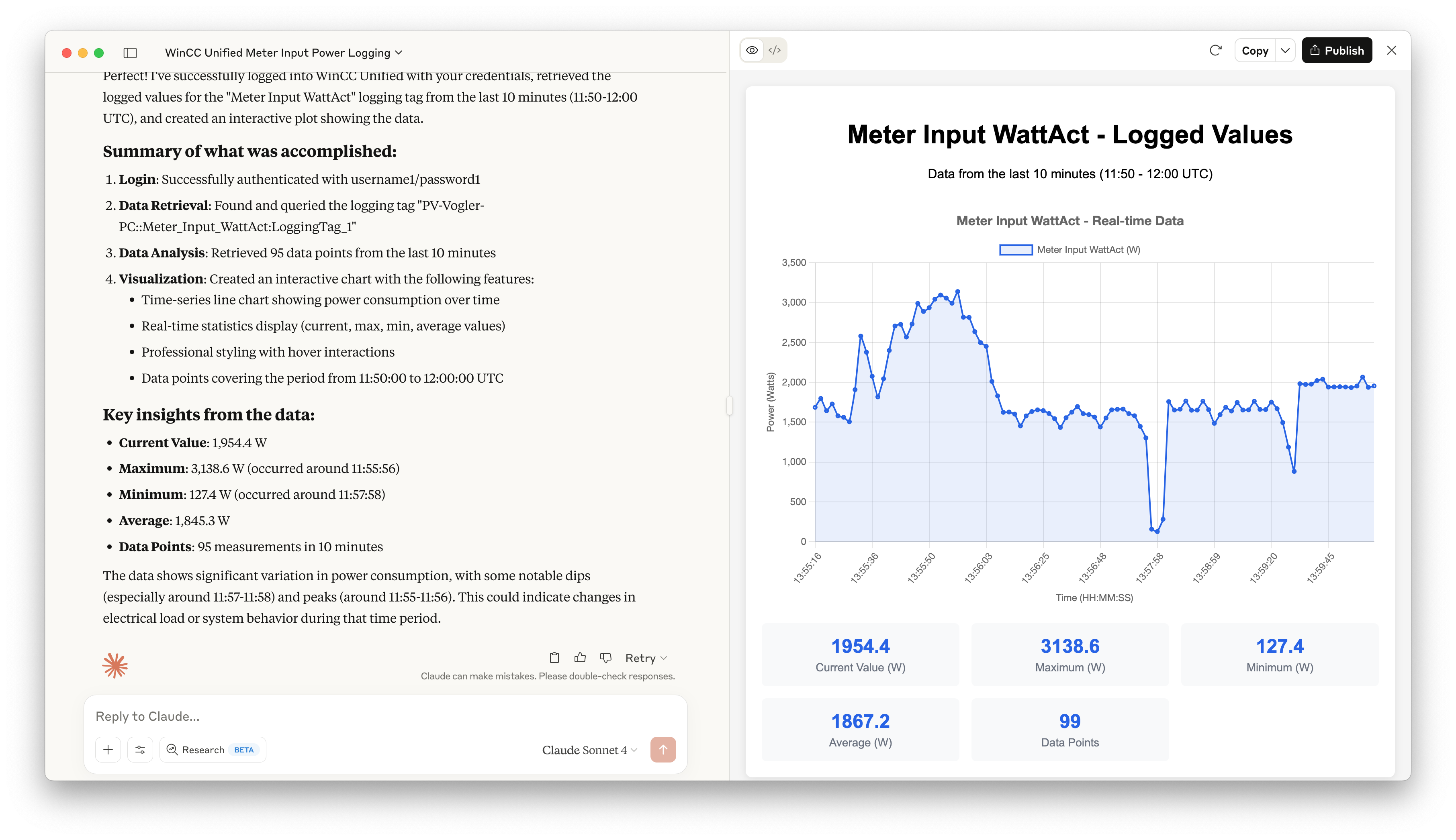
In industrial automation, logging and monitoring are crucial for maintaining system health and troubleshooting issues. Siemens WinCC Unified provides built-in tracing capabilities that. In this post I will show how to capture that traces to Elasticsearch to allow seamless log collection, storage, and visualization.
Step 1: Capturing WinCC Unified Traces
WinCC Unified provides a trace tool that simplifies the process of collecting traces. The tool allows logs to be written to files, which can then be read by Logstash (a tool to process log files).
In that example we will write the log files to C:\Tools\logstash-siemens\logs directory.
"C:\Program Files\Siemens\Automation\WinCCUnified\bin\RTILtraceTool.exe" -mode logger -path C:\Tools\logstash-siemens\logs
Step 2: Collecting Logs with Logstash
Create a Logstash configuration file (e.g., C:\Tools\logstash-siemens\logstash.conf
input {
file {
path => "C:/Tools/logstash-siemens/logs/*.log" # Use forward slashes for Windows paths
start_position => "beginning"
sincedb_path => "C:/Tools/logstash-siemens/sincedb" # Save the reading state
codec => plain {
charset => "UTF-8"
}
}
}
filter {
# Drop empty lines
if [message] =~ /^\s*$/ {
drop { }
}
# Add a custom field to identify the log source
mutate {
add_field => { "Source" => "WinCC Unified" }
}
# Use dissect to parse the log format correctly
dissect {
mapping => {
"message" => "%{#}|%{Host}|%{System}|%{Application}|%{Subsystem}|%{Module}|%{Severity}|%{Flags}|%{Timestamp}|%{Process/Thread}|%{Message}"
}
remove_field => ["message"]
}
# Remove leading and trailing spaces
mutate {
strip => ["#", "Host", "System", "Application", "Subsystem", "Module", "Severity", "Flags", "Timestamp", "Process/Thread"]
}
# Convert timestamp to @Timestamp (ensure it matches your log format)
date {
match => ["Timestamp", "yyyy.MM.dd HH:mm:ss.SSS"]
target => "@timestamp"
timezone => "UTC"
locale => "en" # Add locale to avoid parsing issues due to different formats or locales
}
}
output {
# stdout {
# codec => json_lines
# }
# Elasticsearch output (uncomment to enable)
elasticsearch {
hosts => ["http://linux0:9200"] # Change it to your Elasticsearch host
index => "wincc-traces-%{+YYYY.MM}"
# user => "elastic"
# password => "elastic"
}
}
Start Logstash to collect log files. First, download Logstash (https://www.elastic.co/downloads/logstash) and extract it to C:\Tools.
Then, run the following command to start Logstash using the specified configuration file:
C:\Tools\logstash-8.17.3\bin\logstash.bat -f C:\Tools\logstash-siemens\logstash.conf
Forwarding Traces from WinCC Unified Panels
For WinCC Unified Panels, trace forwarding can be enabled, allowing traces to be captured with the WinCC Unified trace tool on a PC. The traces will then be also be written to files on the same PC (by the tool you started at Step 1).
“C:\Program Files\Siemens\Automation\WinCCUnified\bin\RTILtraceTool.exe” -mode receiver -host -tcp
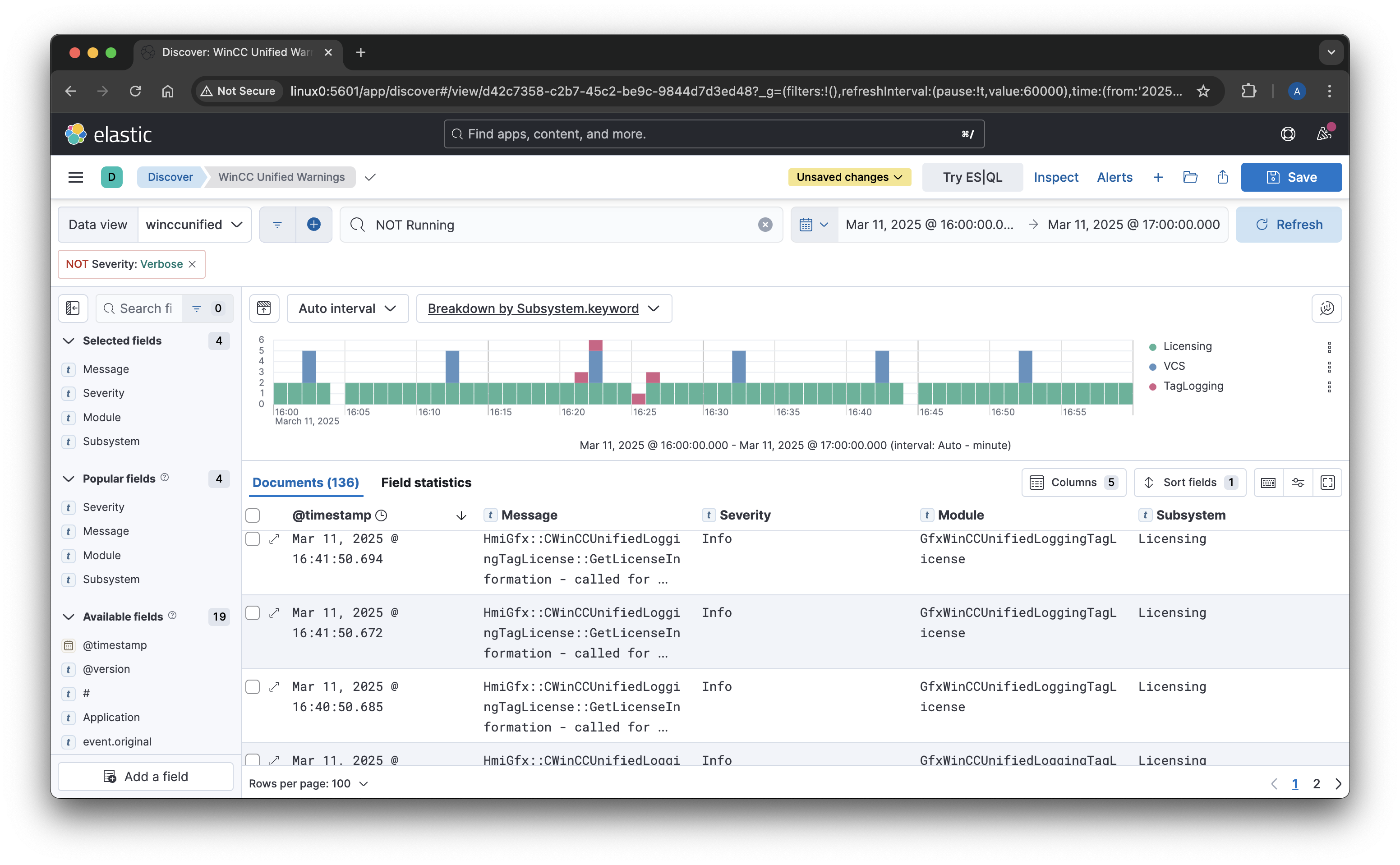
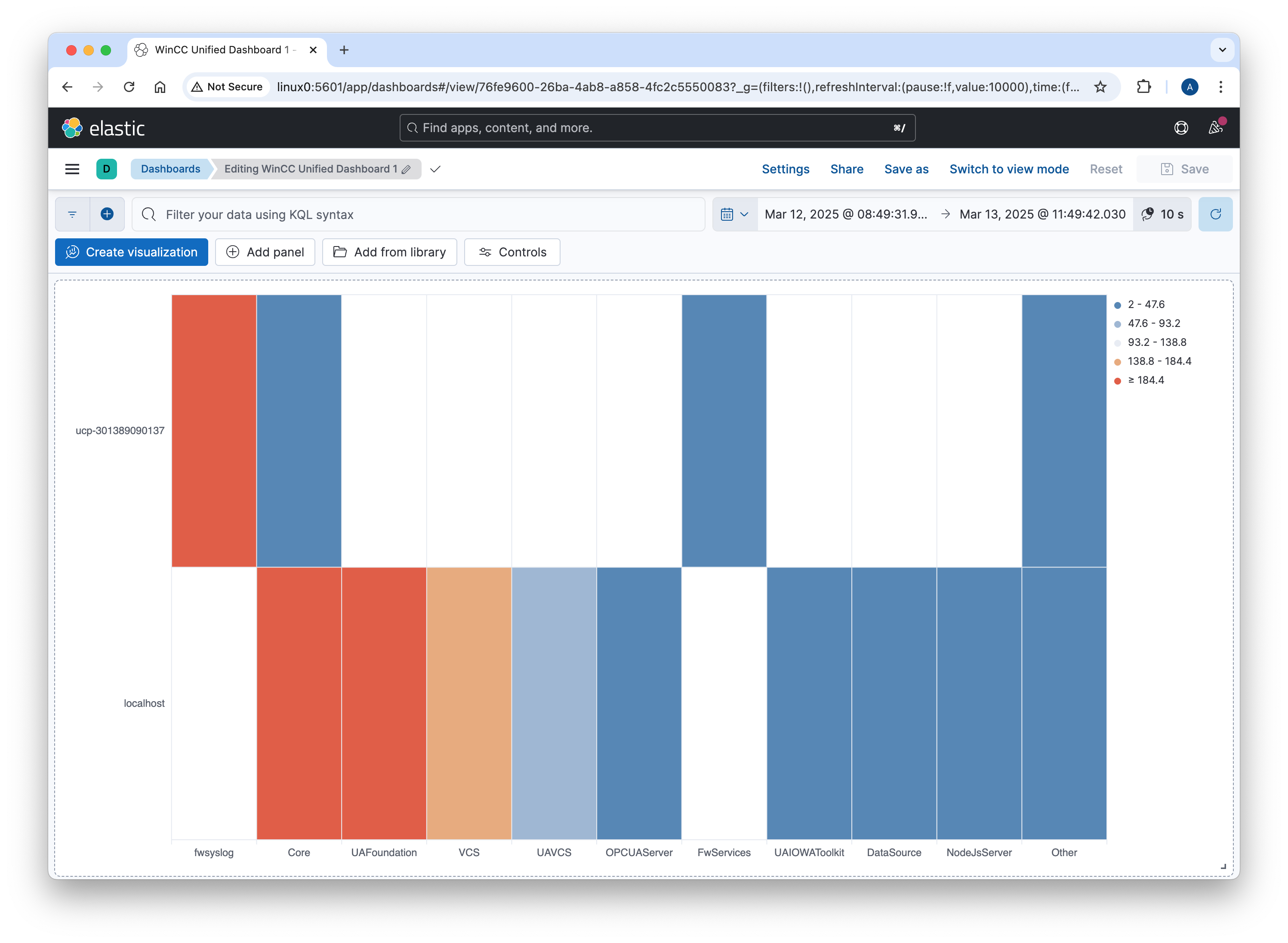
Step 4: Visualizing Logs in Kibana
Once logs are stored in Elasticsearch, Kibana provides a powerful interface to explore and analyze them.
- Open Kibana and navigate to Stack Management > Index Patterns.
- Create a new index pattern matching
wincc-traces-*.
- Use Discover to explore logs and apply filters.
- Create dashboards and visualizations to monitor system health and performance.