Category Archives: Frankenstein
How to log OPC UA tag values to Apache Kafka…
In this article we use the Frankenstein Automation Gateway to subscribe to one public available OPC UA server (milo.digitalpetri.com) and log tag values to Apache Kafka. Additionally we show how you can create a Stream in Apache Kafka based on the OPC UA values coming from the milo OPC UA server and query those stream with KSQL.
Setup Apache Kafka
We have used the all-in-one Docker compose file from confluent to quickly setup Apache Kafka and KSQL. Be sure that you set your resolvable hostname or IP address of your server in the docker-compose.yml file. Otherwise Kafka clients cannot connect to the broker.
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://192.168.1.18:9092
Setup Frankenstein
Install Java 11 (for example Amazon Corretto) and Gradle for Frankenstein. Unzip Gradle to a folder and set your PATH variable to point to the bin directory of Gradle.
Then clone the source of Frankenstein and compile it with Gradle:
git clone https://github.com/vogler75/automation-gateway.git
cd automation-gateway/source/app
gradle buildThere is a example config-milo-kafka.yaml file in the automation-gateway/source/app directory which you can use by setting the environment variable GATEWAY_CONFIG.
export GATEWAY_CONFIG=config-milo-kafka.yaml
In this config file we use a public Eclipse Milo OPC UA server. The Id of this connection is “milo“.
OpcUaClient:
- Id: "milo"
Enabled: true
LogLevel: INFO
EndpointUrl: "opc.tcp://milo.digitalpetri.com:62541/milo"
UpdateEndpointUrl: false
SecurityPolicyUri: http://opcfoundation.org/UA/SecurityPolicy#None
UsernameProvider:
Username: user1
Password: passwordHere is the configuration of the Kafka Logger where you can configure what OPC UA tags should be published to Kafka. In that case we use a OPC UA Browse Path and a wildcard to use all variables below one node.
Database:
Logger:
- Id: kafka1
Type: Kafka
Enabled: true
Servers: server2:9092
WriteParameters:
QueueSize: 20000
BlockSize: 10000
Logging:
- Topic: opc/milo/path/Objects/Dynamic/+Start Frankenstein
export GATEWAY_CONFIG=config-milo-kafka.yaml
gradle runCreate a Stream in KSQL
Start a CLI session to KSQL on the host where the Kafka containers run:
docker exec -ti ksqldb-cli ksql http://ksqldb-server:8088Create a stream for the Kafka “milo” topic
CREATE STREAM milo(
browsePath VARCHAR KEY,
sourceTime VARCHAR,
value DOUBLE,
statusCode VARCHAR
) WITH (
KEY_FORMAT='KAFKA',
KAFKA_TOPIC='milo',
VALUE_FORMAT='JSON',
TIMESTAMP='sourceTime',TIMESTAMP_FORMAT='yyyy-MM-dd''T''HH:mm:ss.nX'
);Then you can execute a KSQL query to get the stream of values from the OPC UA server:
ksql> select browsepath, sourcetime, value from milo emit changes;
+---------------------------------------+---------------------------------------+---------------------------------------+
|BROWSEPATH |SOURCETIME |VALUE |
+---------------------------------------+---------------------------------------+---------------------------------------+
|Objects/Dynamic/RandomInt32 |2021-05-02T11:29:04.405465Z |1489592303 |
|Objects/Dynamic/RandomInt64 |2021-05-02T11:29:04.405322Z |-6.3980451035323023E+18 |
|Objects/Dynamic/RandomFloat |2021-05-02T11:29:04.405350Z |0.7255345 |
|Objects/Dynamic/RandomDouble |2021-05-02T11:29:04.405315Z |0.23769088795602633 |
Automation Gateway with Apache IoTDB…
The Frankenstein Automation Gateway can now write OPC UA tag values to the Apache IoTDB. Did some rough performance tests with 50 OPC UA servers and one IoTDB… the IoTDB is pretty impressive fast. Also the data model and terminology is interesting and it seems to fit good to a hirarchical structure in OPC UA.
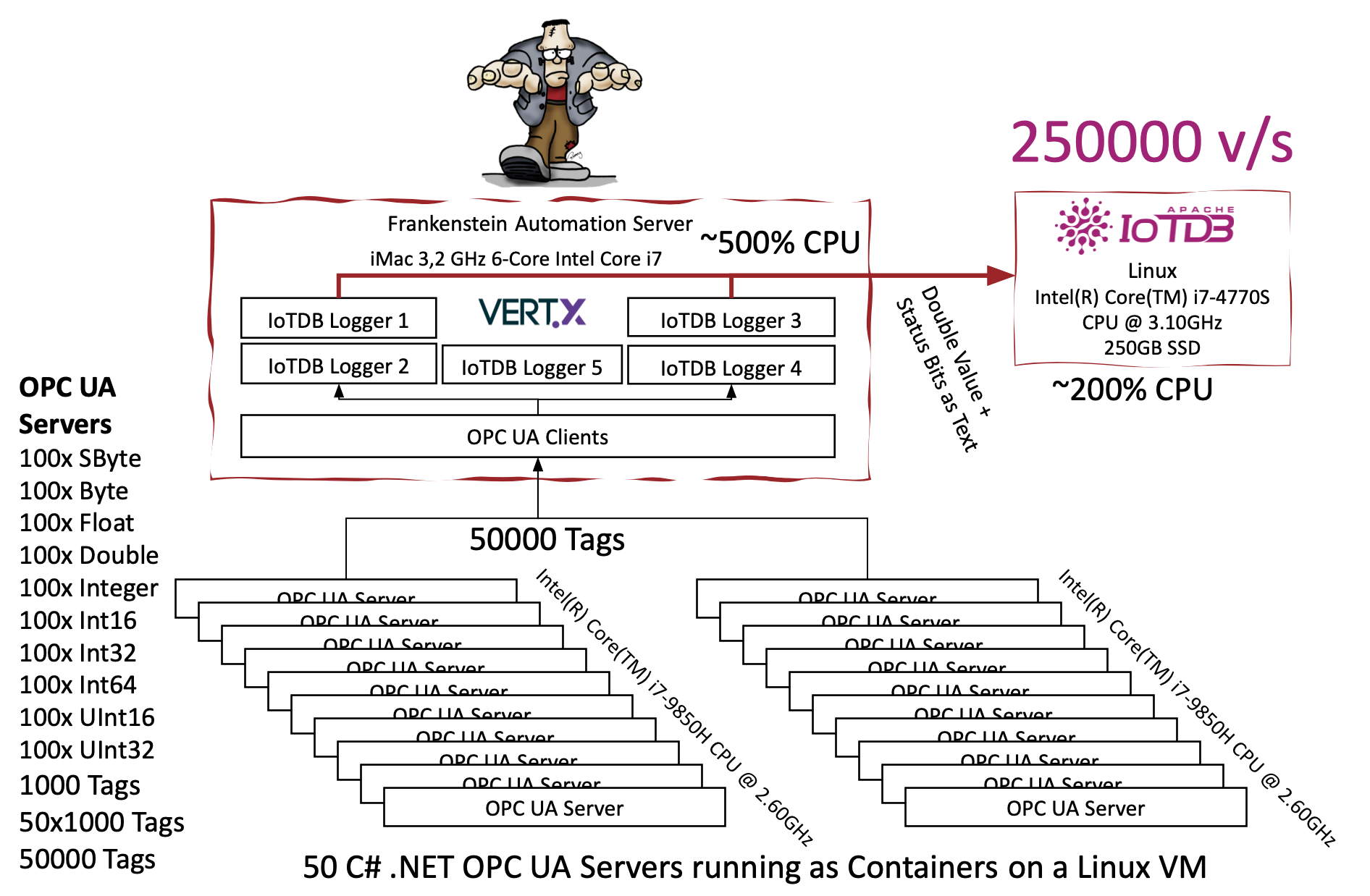
In this lab I have connected 50 OPC UA servers (based on a .NET OPC UA server example) to Frankenstein. Each OPC UA server publishes 1000 tags of different type, so in summary we have 50000 tags connected to Frankenstein. The publish rate can be adjusted by setting an OPC UA tag. Sure, we do that via GraphQL over Frankenstein. On my commodity hardware I ended with writing about 250Khz to the IoTDB with an CPU load of ~200%. So, I assume the IoTDB is able to handle much more value changes per second.
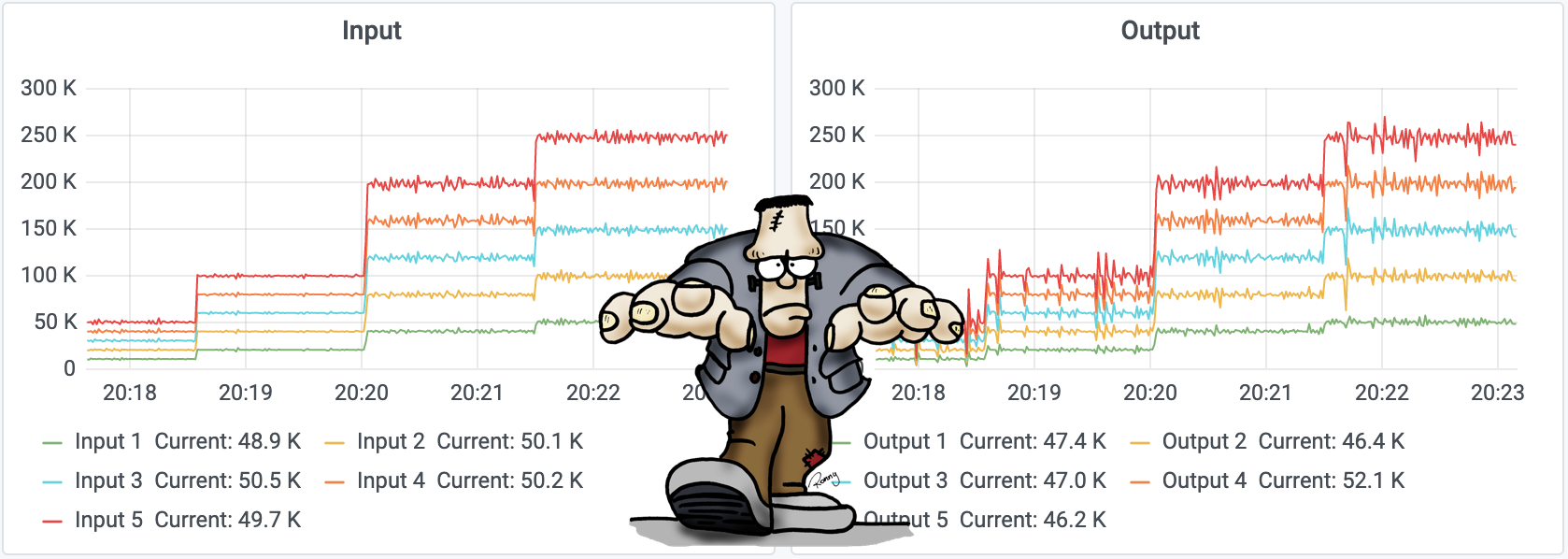
Figured out that one DB Logger inside of Frankenstein roughly is able to handle 100000 events per second. We can spawn multiple DB Logger for scalabilty. Vert.X can then use multiple cores (Vert.X calls this pattern the Multi-Reactor Pattern to distinguish it from the single threaded reactor pattern).
Just to note: there is only a memory buffer implemented, so if the DB is down, then the values will be lost if the buffer runs out of space. But I think to handle such situations it would make sense to put Apache Kafka between the Gateway and the Database.
GraphQL Query to set the simulation interval:
query ($v: String) {
Systems {
opc1 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc2 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc3 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc4 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc5 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc6 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc7 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc8 { Demo { SimulationInterval { SetValue(Value: $v) } } }
opc9 { Demo { SimulationInterval { SetValue(Value: $v) } } }
...
}
}
Query Variables: {"v": "250"}