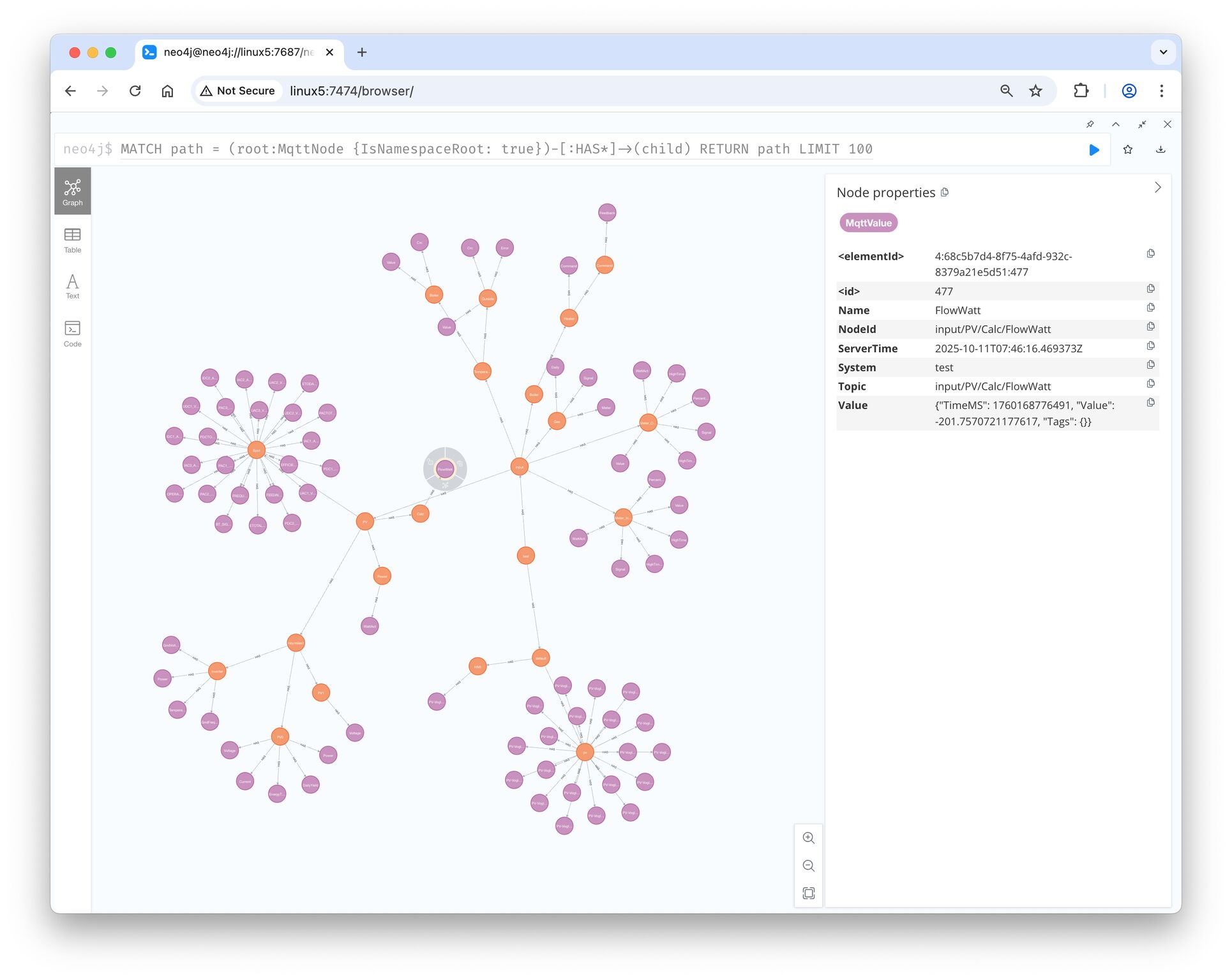
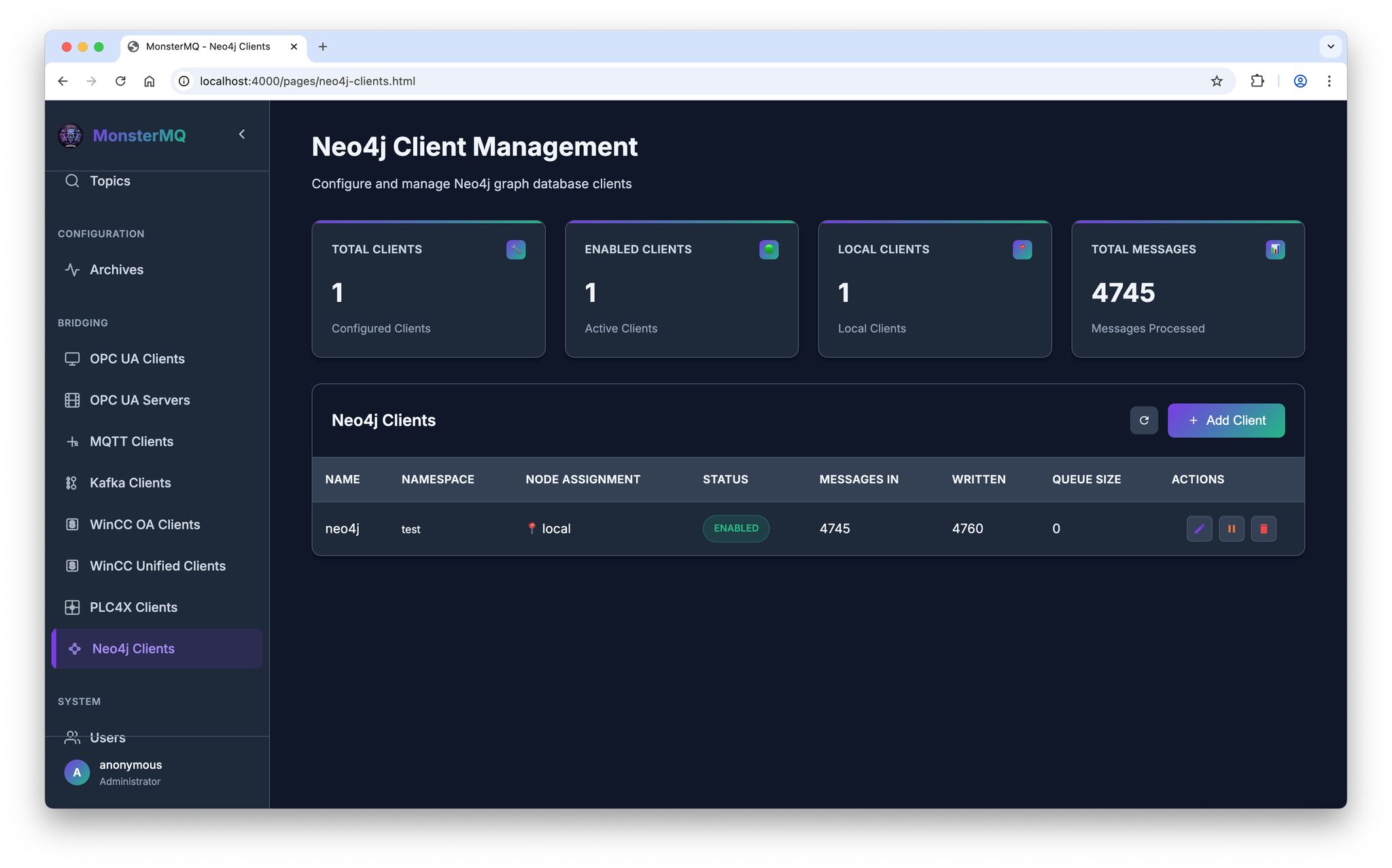
Built in Go, based on another open-source project (Mochi MQTT), implemented to expose the same GraphQL interface as the full MonsterMQ broker and having the same storage backend (SQLite, Postgres, MongoDB).
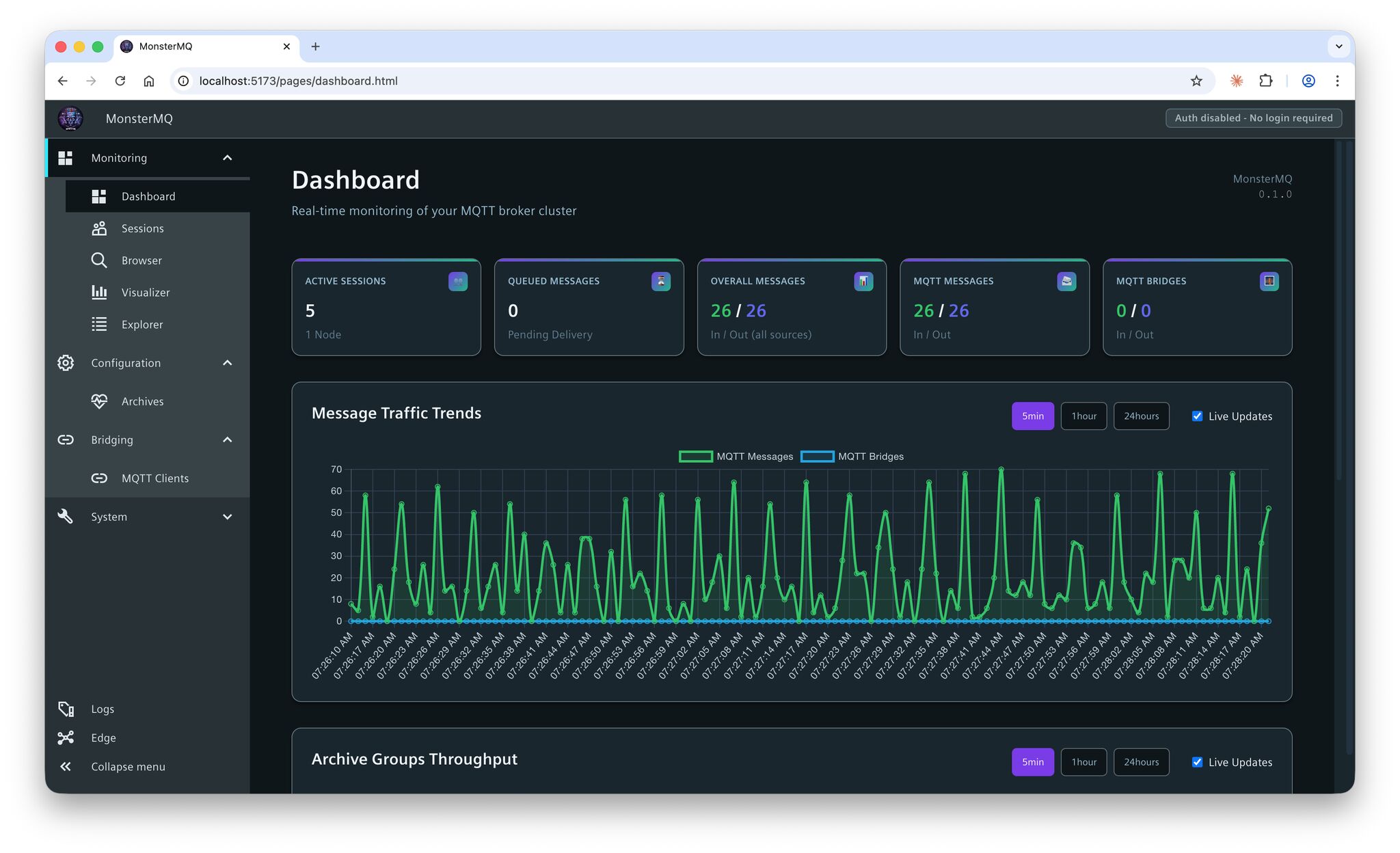
What does that mean in practice? You can run a lightweight MonsterMQ instance at the edge and monitor and configure it from the same MonsterMQ dashboard and having the data in the same storage format. No separate tooling needed.
Current state:
- 👉 Single binary 25M
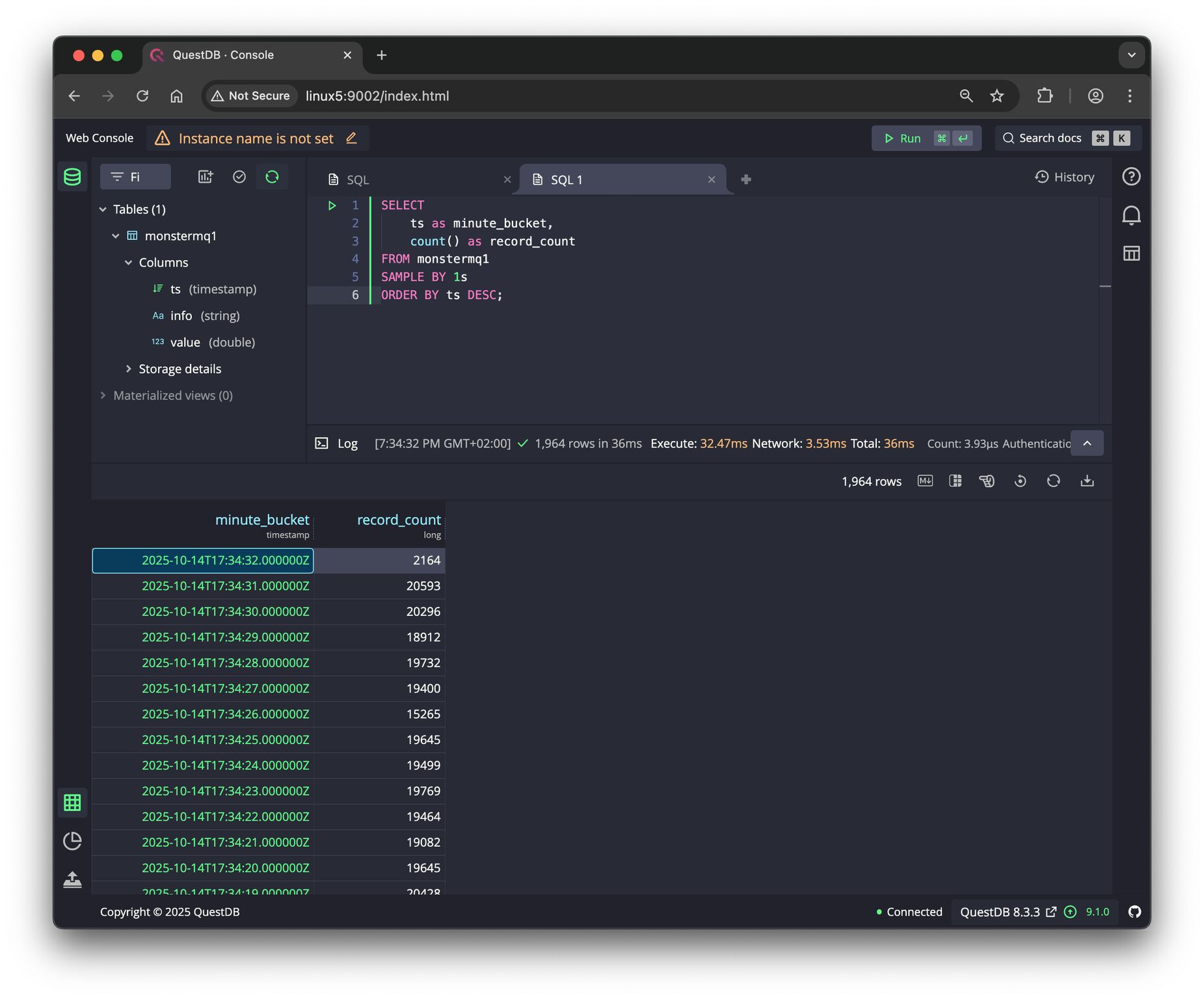
- 👉 In memory last value storage
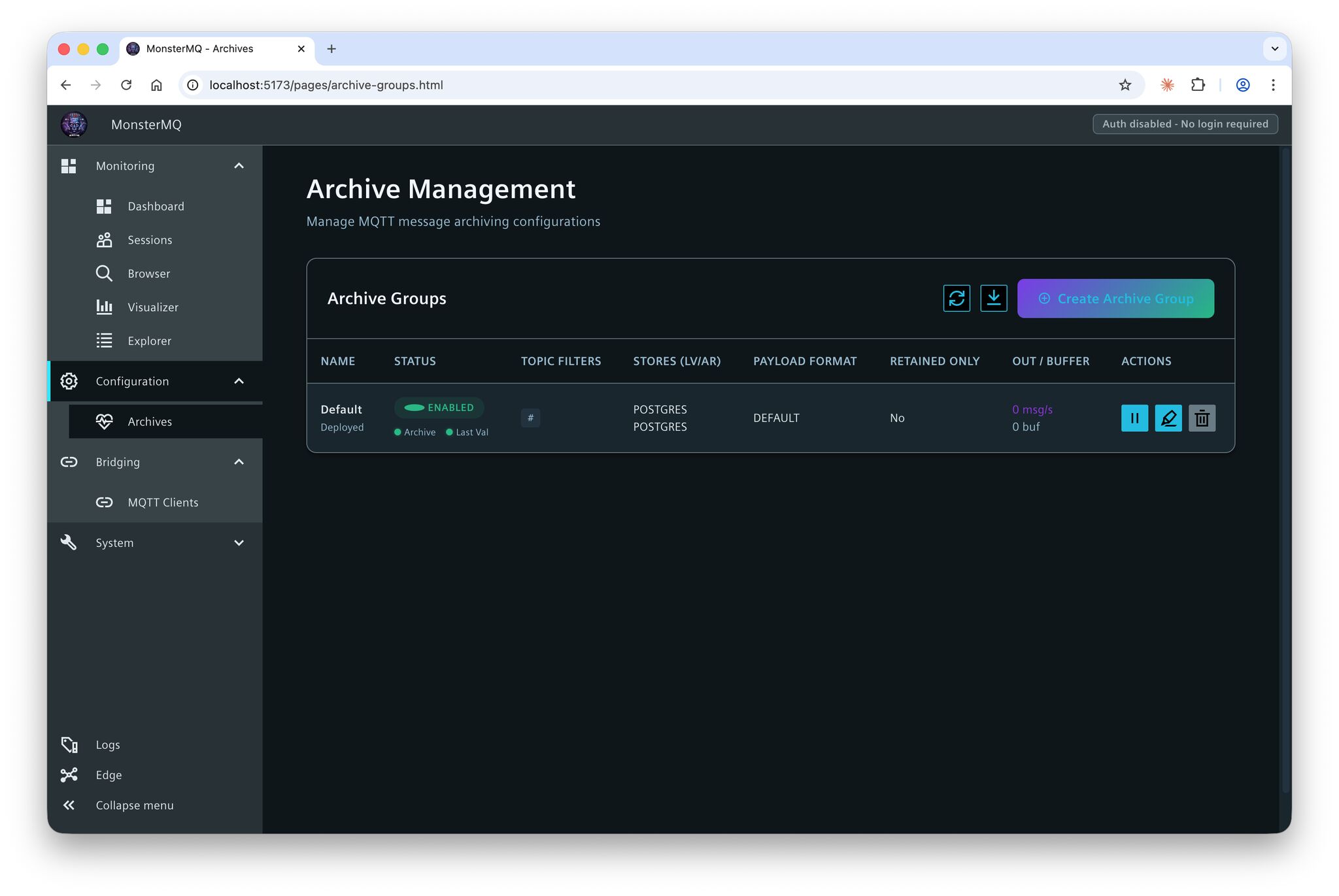
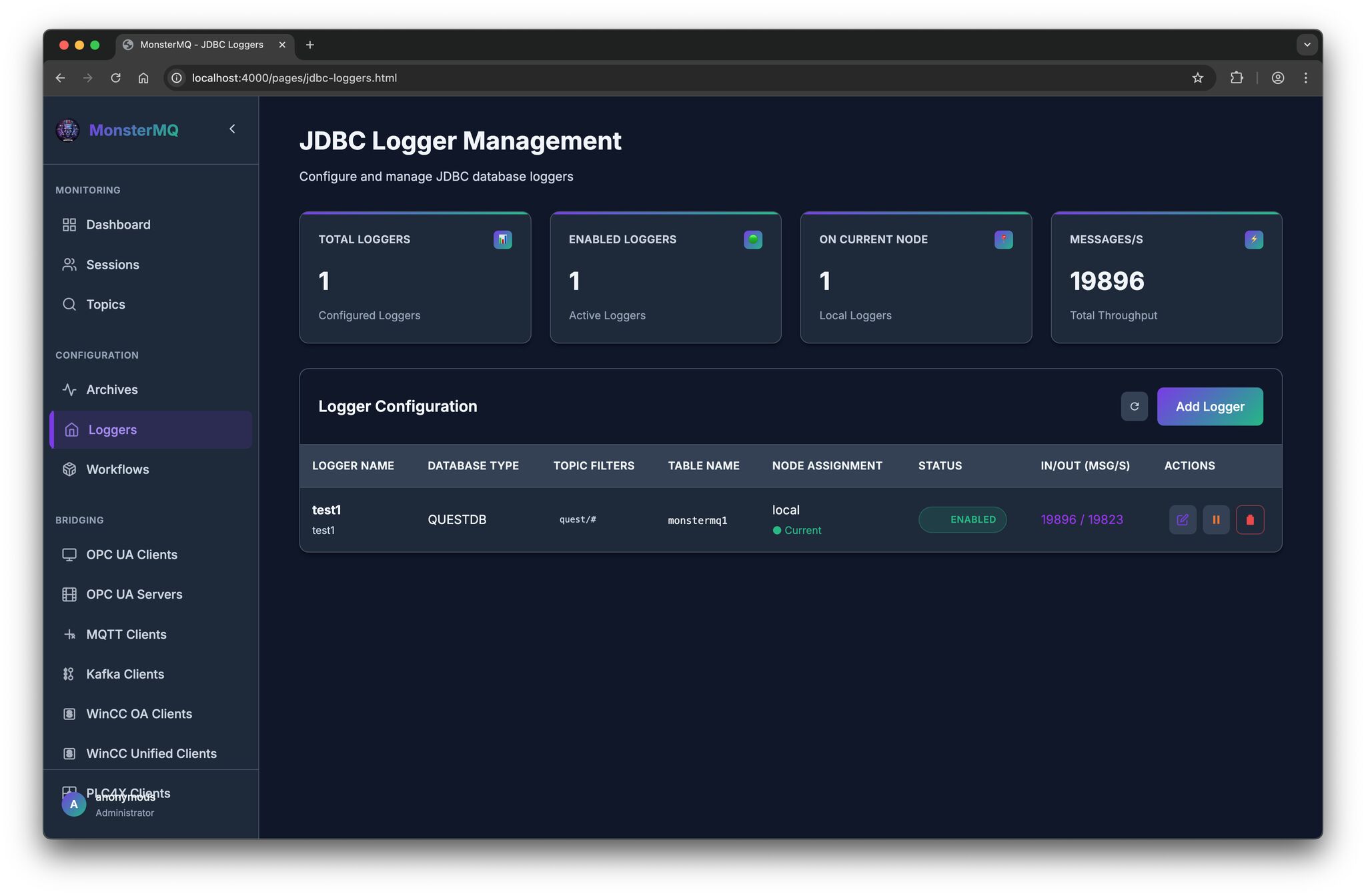
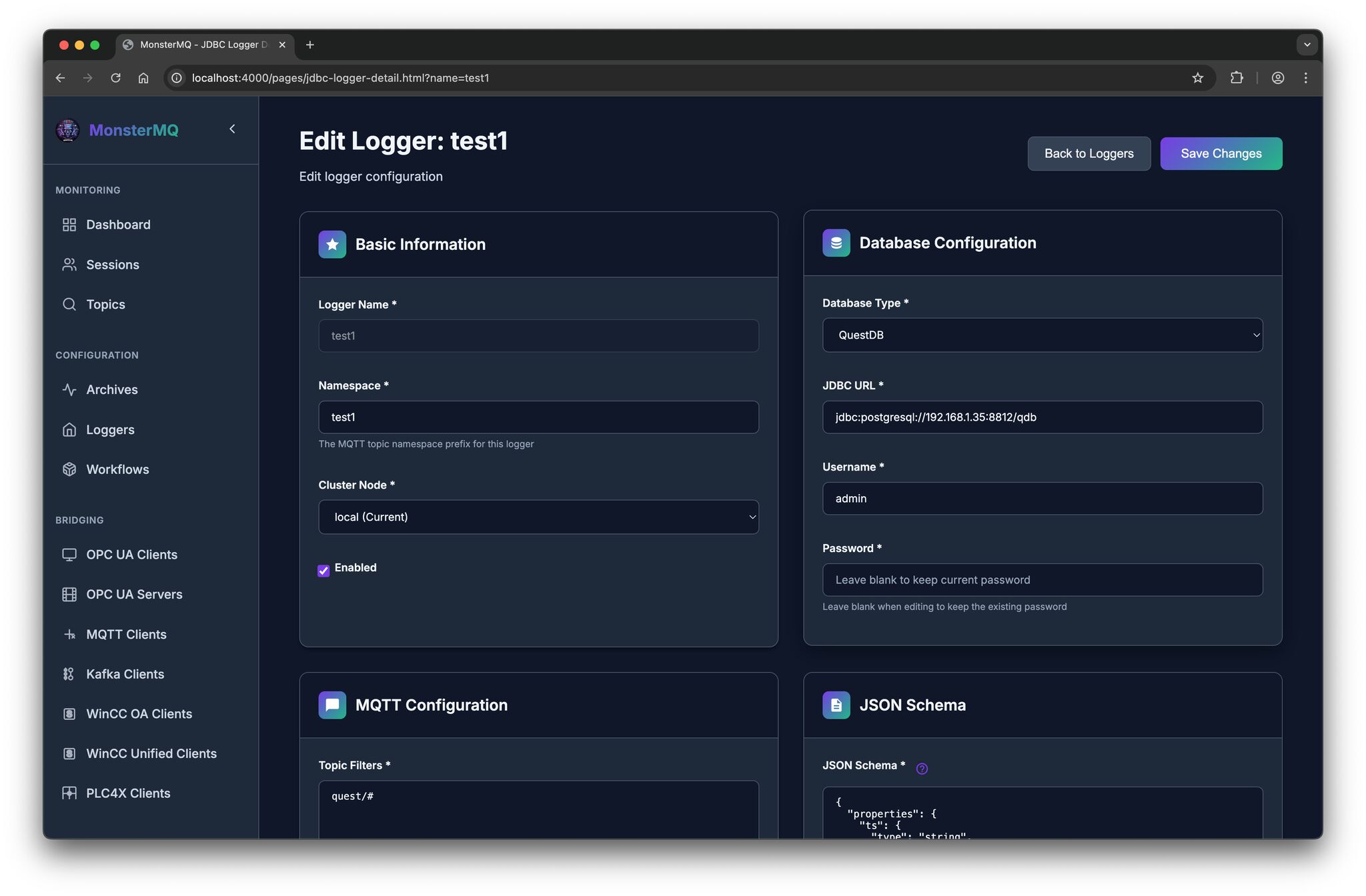
- 👉 Archiver for SQLite, PostgreSQL and MongoDB.
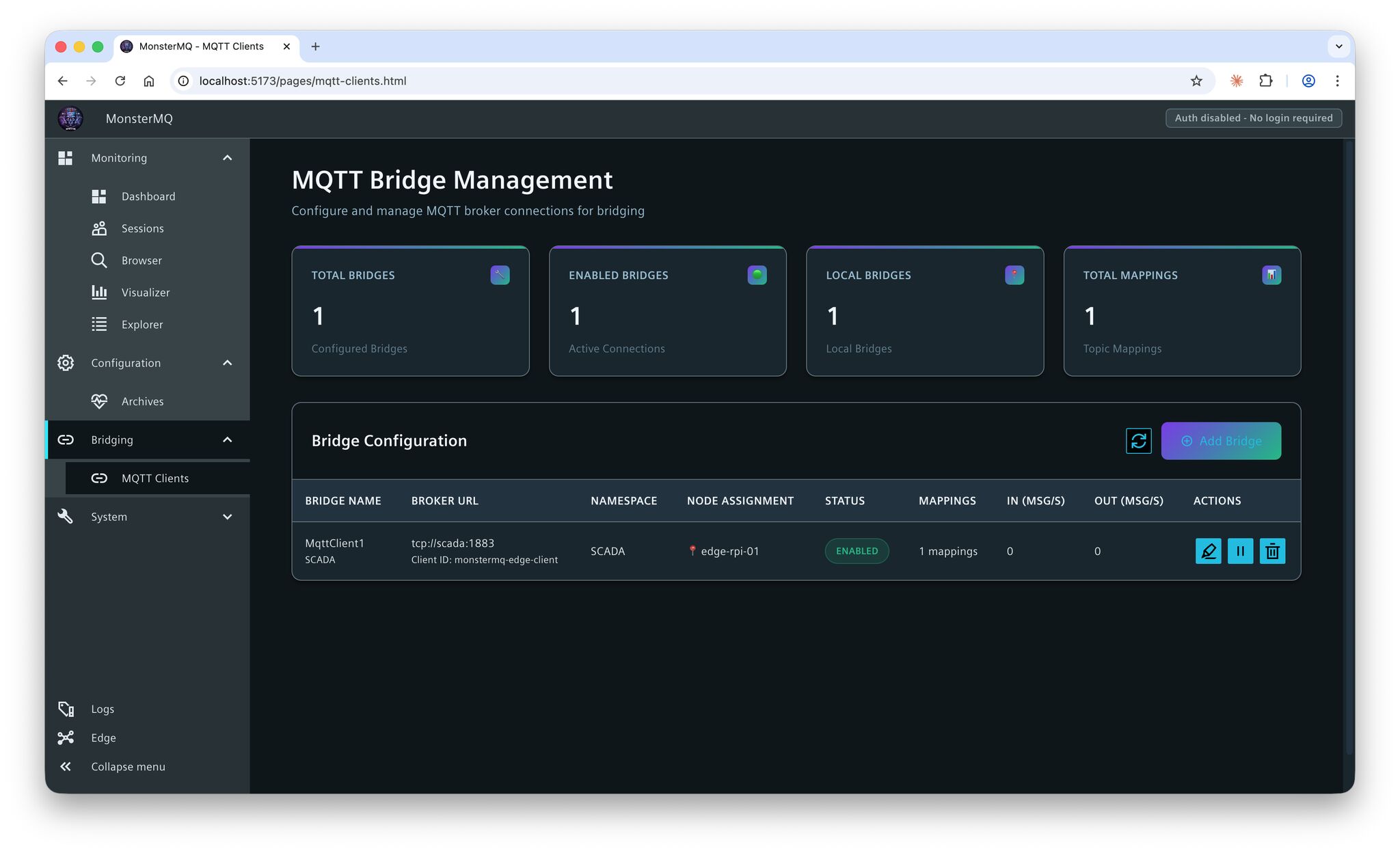
- 👉 MQTT Bridge available to pub/sub from/to other brokers.
- 👉 Backend storage options: SQLite, Postgres or MongoDB
- 👉 Same GraphQL interface – compatible with the existing dashboard
Very early stage, and just an experiment for now. What do you think about it?
#MonsterMQ #MqttClaw #MQTT #Edge #EdgeComputing #Go