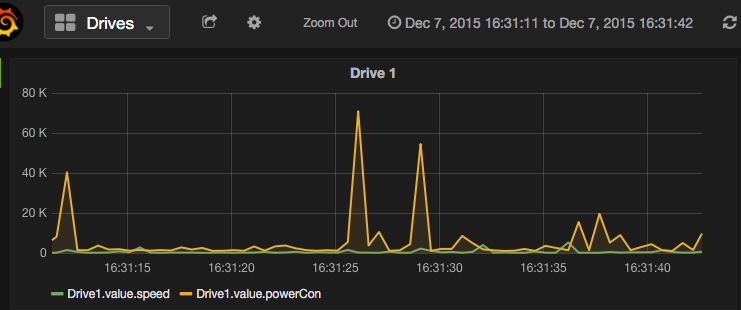
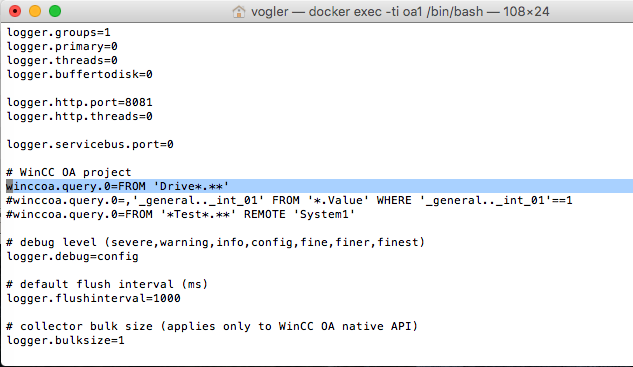
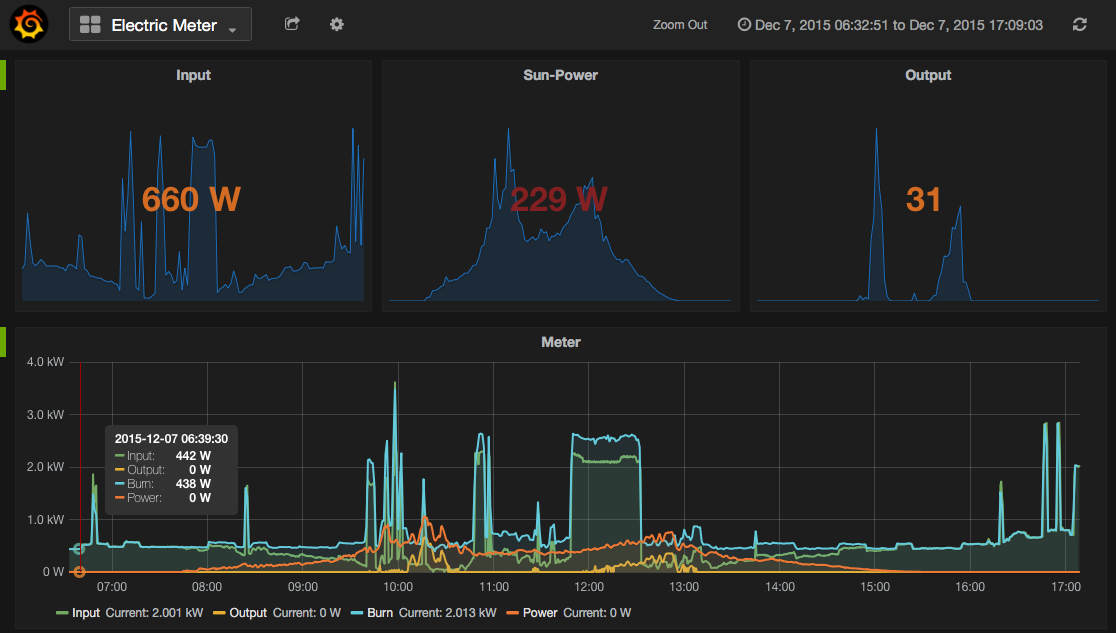
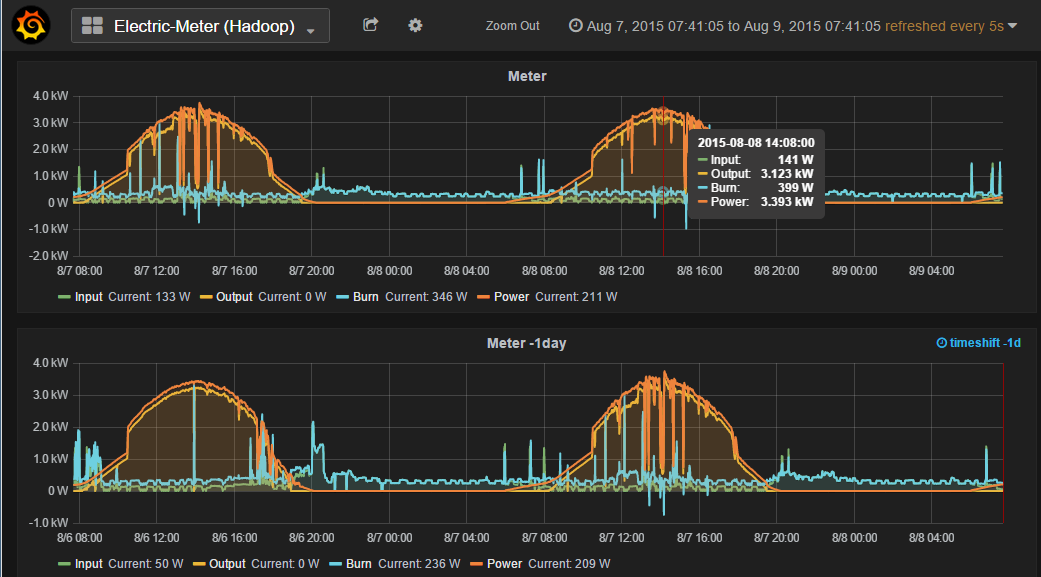
Complex Event Processing (CEP) and event series analysis are used for detecting situations among events. EsperTech provides the Event Processing Language (EPL) designed for concisely expressing situations and fast execution against both historical and currently-arriving events (Espertech.com).
The Esper EPL is quite powerful – details can be found in the Esper documentation. Found also some slides about Esper. The EPL is a CQL (continuous query language), after a statement is created it is running coninously and results are streamed to listeners – in this prototype a listener is sending the results back to WinCC OA datapoints.
A WinCCOA API-Frontend-Manager gathers all value changes from WinCC OA and publishes it by ZeroMQ. The WinCC OA CEP Manager, with the open source Esper-Engine, subscribes to the Frontend-Manager to get the value changes. The advantage is that many subscribers can be connected to the Frontend-Manager, without increasing the load on the WinCC OA system (based on the ideas from CERN).
With the WinCC OA CEP Manager we can define EPL / CQL statements in WinCC OA and the result streams are passed back to WinCC OA on datapoints, where the results can be processed further.
Some simple EPL examples:
Calculate 5 minute average values with intermediate results every 1 minute:
select avg(value), min(value), max(value) from event(tag='System1:Meter_Input.Watt').win:time(5 min) output snapshot at (*/1, *, *, *, *)
With pattern matching complex event sequences can be observed with EPL. A simple example is: detect if datapoint B is set after datapoint A (A->B), and its value is higher than the value of A.
select a.value, b.value from pattern [a=Event(tag='System1:Analog1.Input') -> every b=Event(tag='System1:ExampleDP_Trend1.' and b.value>a.value)]
Get a notification when a datapoint is changing more than 100 times within 10 seconds:
select tag, count(value) from Event.win:time_batch(10 sec) group by tag having count(*) > 100
Get a notification when a datapoint changes and there is no following value change within the next 10 seconds. For example: if meters are normally changing every 5 seconds, possible broken meters/interfaces can be detected with EPL:
select a.tag, count(*) from pattern [every a=Event -> (timer:interval(10 sec) and not Event(tag=a.tag))] group by a.tag
Other examples can be found here.
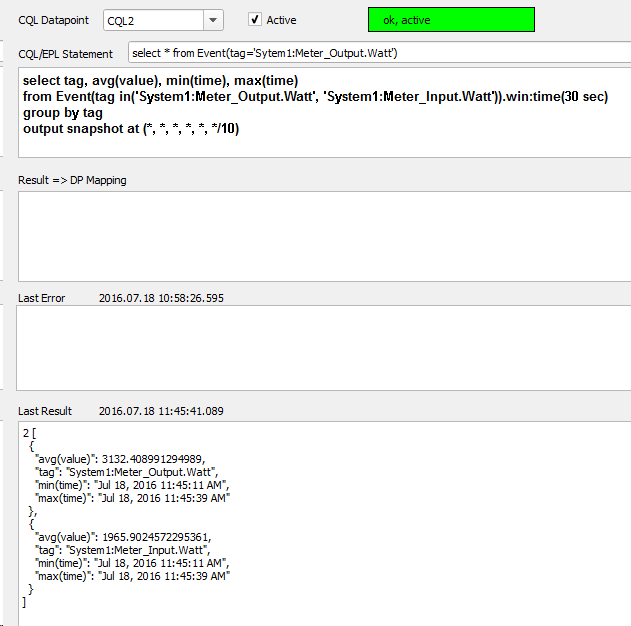
Attached is a screenshot of a simple panel where EPL statements can be defined and observed.
Other examples for CEP with Esper: http://www.adrianmilne.com/complex-event-processing-made-easy/